


Scalability is now at the forefront of the technical discussion in the cryptocurrency scene. The Bitcoin blockchain is currently over 12 GB in size, requiring a period of several days for a new bitcoind node to fully synchronize, the UTXO set that must be stored in RAM is approaching 500 MB, and continued software improvements in the source code are simply not enough to alleviate the trend. With every passing year, it becomes more and more difficult for an ordinary user to locally run a fully functional Bitcoin node on their own desktop, and even as the price, merchant acceptance and popularity of Bitcoin has skyrocketed the number of full nodes in the network has essentially stayed the same since 2011. The 1 MB block size limit currently puts a theoretical cap on this growth, but at a high cost: the Bitcoin network cannot process more than 7 transactions per second. If the popularity of Bitcoin jumps up tenfold yet again, then the limit will force the transaction fee up to nearly a dollar, making Bitcoin less useful than Paypal. If there is one problem that an effective implementation of cryptocurrency 2.0 needs to solve, it is this.
The reason why we in the cryptocurrency spaceare having these problems, and are making so little headway toward coming up with a solution, is that there one fundamental issue with all cryptocurrency designs that needs to be addressed. Out of all of the various proof of work, proof of stake and reputational consensus-based blockchain designs that have been proposed, not a single one has managed to overcome the same core problem: that every single full node must process every single transaction. Having nodes that can process every transaction, even up to a level of thousands of transactions per second, is possible; centralized systems like Paypal, Mastercard and banking servers do it just fine. However, the problem is that it takes a large quantity of resources to set up such a server, and so there is no incentive for anyone except a few large businesses to do it. Once that happens, then those few nodes are potentially vulnerable to profit motive and regulatory pressure, and may start making theoretically unauthorized changes to the state, like giving themselves free money, and all other users, which are dependent on those centralized nodes for security, would have no way of proving that the block is invalid since they do not have the resources to process the entire block.
In Ethereum, as of this point, we have no fundamental improvements over the principle that every full node must process every transaction. There have been ingenious ideas proposed by various Bitcoin developers involving multiple merge-mined chains with a protocol for moving funds from one chain to another, and these will be a large part of our cryptocurrency research effort, but at this point research into how to implement this optimally is not yet mature. However, with the introduction of Block Protocol 2.0 (BP2), we have a protocol that, while not getting past the fundamental blockchain scalability flaw, does get us partway there: as long as at least one honest full node exists (and, for anti-spam reasons, has at least 0.01% mining power or ether ownership), “light clients” that only download a small amount of data from the blockchain can retain the same level of security as full nodes.
What Is A Light Client?
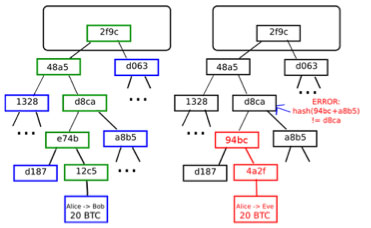
The basic idea behind a light client is that, thanks to a data structure present in Bitcoin (and, in a modified form, Ethereum) called a Merkle tree, it is possible to construct a proof that a certain transaction is in a block, such that the proof is much smaller than the block itself. Right now, a Bitcoin block is about 150 KB in size; a Merkle proof of a transaction is about half a kilobyte. If Bitcoin blocks become 2 GB in size, the proofs might expand to a whole kilobyte. To construct a proof, one simply needs to follow the “branch” of the tree all the way up from the transaction to the root, and provide the nodes on the side every step of the way. Using this mechanism, light clients can be assured that transactions sent to them (or from them) actually made it into a block.
This makes it substantially harder for malicious miners to trick light clients. If, in a hypothetical world where running a full node was completely impractical for ordinary users, a user wanted to claim that they sent 10 BTC to a merchant with not enough resources to download the entire block, the merchant would not be helpless; they would ask for a proof that a transaction sending 10 BTC to them is actually in the block. If the attacker is a miner, they can potentially be more sophisticated and actually put such a transaction into a block, but have it spend funds (ie. UTXO) that do not actually exist. However, even here there is a defense: the light client can ask for a second Merkle tree proof showing that the funds that the 10 BTC transaction is spending also exist, and so on down to some safe block depth. From the point of view of a miner using a light client, this morphs into a challenge-response protocol: full nodes verifying transactions, upon detecting that a transaction spent an output that does not exist, can publish a “challenge” to the network, and other nodes (likely the miner of that block) would need to publish a “response” consisting of a Merkle tree proof showing that the outputs in question do actually exist in some previous block. However, there is one weakness in this protocol in Bitcoin: transaction fees. A malicious miner can publish a block giving themselves a 1000 BTC reward, and other miners running light clients would have no way of knowing that this block is invalid without adding up all of the fees from all of the transactions themselves; for all they know, someone else could have been crazy enough to actually add 975 BTC worth of fees.
BP2
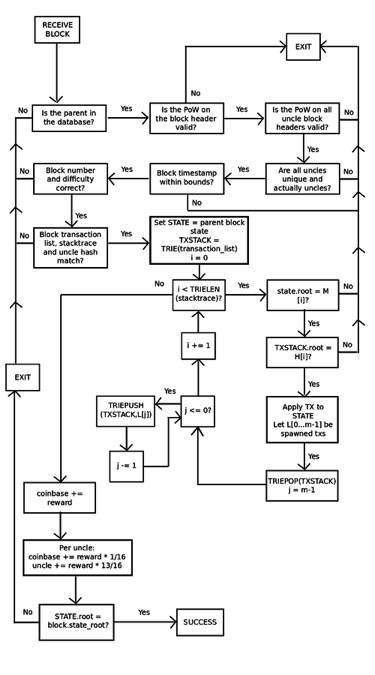
With the previous Block Protocol 1.0, Ethereum was even worse; there was no way for a light client to even verify that the state tree of a block was a valid consequence of the parent state and the transaction list. In fact, the only way to get any assurances at all was for a node to run through every transaction and sequentially apply them to the parent state themselves. BP2, however, adds some stronger assurances. With BP2, every block now has three trees: a state tree, a transaction tree, and a stack trace tree providing the intermediate root of the state tree and the transaction tree after each step. This allows for a challenge-response protocol that, in simplified form, works as follows:
-
Miner M publishes block B. Perhaps the miner is malicious, in which case the block updates the state incorrectly at some point.
-
Light node L receives block B, and does basic proof of work and structural validity checks on the header. If these checks pass, then L starts off treating the block as legitimate, though unconfirmed.
-
Full node F receives block B, and starts doing a full verification process, applying each transaction to the parent state, and making sure that each intermediate state matches the intermediate state provided by the miner. Suppose that F finds an inconsistency at point k. Then, F broadcasts a “challenge” to the network consisting of the hash of B and the value k.
-
L receives the challenge, and temporarily flags B as untrustworthy.
-
If F’s claim is false, and the block is valid at that point, then M can produce a proof of localized consistency by showing a Merkle tree proof of point k in the stack trace, point k+1 in the stack trace, and the subset of Merkle tree nodes in the state and transaction tree that were modified during the process of updating from k to k+1. L can then verify the proof by taking M’s word on the validity of the block up to point k, manually running the update from k to k+1 (this consists of processing a single transaction), and making sure the root hashes match what M provided at the end. L would, of course, also check that the Merkle tree proof for the values at state k and k+1 is valid.
-
If F’s claim is true, then M would not be able to come up with a response, and after some period of time L would discard B outright.
Note that currently the model is for transaction fees to be burned, not distributed to miners, so the weakness in Bitcoin’s light client protocol does not apply. However, even if we decided to change this, the protocol can easily be adapted to handle it; the stack trace would simply also keep a running counter of transaction fees alongside the state and transaction list. As an anti-spam measure, in order for F’s challenge to be valid, F needs to have either mined one of the last 10000 blocks or have held 0.01% of the total supply of ether for at least some period of time. If a full node sends a false challenge, meaning that a miner successfully responds to it, light nodes can blacklist the node’s public key.
Altogether, what this means is that, unlike Bitcoin, Ethereum will likely still be fully secure, including against fraudulent issuance attacks, even if only a small number of full nodes exist; as long as at least one full node is honest, verifying blocks and publishing challenges where appropriate, light clients can rely on it to point out which blocks are flawed. Note that there is one weakness in this protocol: you now need to know all transactions ahead of time before processing a block, and adding new transactions requires substantial effort to recalculate intermediate stack trace values, so the process of producing a block will be more inefficient. However, it is likely possible to patch the protocol to get around this, and if it is possible then BP2.1 will have such a fix.
Blockchain-based Mining
We have not finalized the details of this, but Ethereum will likely use something similar to the following for its mining algorithm:
-
Let H[i] = sha3(sha3(block header without nonce) ++ nonce ++ i) for i in [0 ...16]
-
Let N be the number of transactions in the block.
-
Let T[i] be the (H[i] mod N)th transaction in the block.
-
Let S be the parent block state.
-
Apply T[0] ... T[15] to S, and let the resulting state be S'.
-
Let x = sha3(S'.root)
-
The block is valid if x * difficulty <= 2^256
This has the following properties:
-
This is extremely memory-hard, even more so than Dagger, since mining effectively requires access to the entire blockchain. However it is parallelizable with shared disk space, so it will likely be GPU-dominated, not CPU-dominated as Dagger originally hoped to be.
-
It is memory-easy to verify, since a proof of validity consists of only the relatively small subset of Patricia nodes that are used while processing T[0] ... T[15]
-
All miners essentially have to be full nodes; asking the network for block data for every nonce is prohibitively slow. Thus there will be a larger number of full nodes in Ethereum than in Bitcoin.
-
As a result of (3), one of the major motivations to use centralized mining pools, the fact that they allow miners to operate without downloading the entire blockchain, is nullified. The other main reason to use mining pools, the fact that they even out the payout rate, can be assomplished just as easily with the decentralized p2pool (which we will likely end up supporting with development resources)
-
ASICs for this mining algorithm are simultaneously ASICs for transaction processing, so Ethereum ASICs will help solve the scalability problem.
From here, there is only really one optimization that can be made: figuring out some way to get past the obstacle that every full node must process every transaction. This is a hard problem; a truly scalable and effective solution will take a while to develop. However, this is a strong start, and may even end up as one of the key ingredients to a final solution.