



One of the key properties that is usually sought for in a cryptoeconomic algorithm, whether a blockchain consensus algorithm such a proof of work or proof of stake, a reputation system or a trading process for something like data transmission or file storage, is the ideal of incentive-compatibility - the idea that it should be in everyone's economic interest to honestly follow the protocol. The key underlying assumption in this goal is the idea that people (or more precisely in this case nodes) are "rational" - that is to say, that people have a relatively simple defined set of objectives and follow the optimal strategy to maximize their achievement of those objectives. In game-theoretic protocol design, this is usually simplified to saying that people like money, since money is the one thing that can be used to help further one's success in almost any objective. In reality, however, this is not precisely the case.
Humans, and even the de-facto human-machine hybrids that are the participants of protocols like Bitcoin and Ethereum, are not perfectly rational, and there are specific deviations from rationality that are so prevalent among users that they cannot be simply categorized as "noise". In the social sciences, economics has responded to this concern with the subfield of behavioral economics, which combines experimental studies with a set of new theoretical concepts including prospect theory, bounded rationality, defaults and heuristics, and has succeeded in creating a model which in some cases considerably more accurately models human behavior.
In the context of cryptographic protocols, rationality-based analyses are arguably similarly suboptimal, and there are particular parallels between some of the concepts; for example, as we will later see, "software" and "heuristic" are essentially synonyms. Another point of interest is the fact that we arguably do not even have an accurate model of what constitutes an "agent", an insight that has particular importance to protocols that try to be "trust-free" or have "no single point of failure".
Traditional models
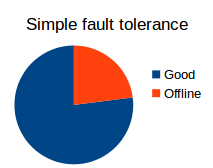
In traditional fault-tolerance theory, there are three kinds of models that are used for determining how well a decentralized system can survive parts of it deviating from the protocol, whether due to malice or simple failure. The first of these is simple fault tolerance. In a simple fault tolerant system, the idea is that all parts of the system can be trusted to do either one of two things: exactly follow the protocol, or fail. The system should be designed to detect failures and recover and route around them in some fashion. Simple fault tolerance is usually the best model for evaluating systems that are politically centralized, but architecturally decentralized; for example, Amazon or Google's cloud hosting. The system should definitely be able to handle one server going offline, but the designers do not need to think about one of the servers becoming evil (if that does happen, then an outage is acceptable until the Amazon or Google team manually figure out what is going on and shut that server down).
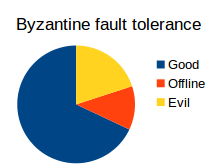
However, simple fault tolerance is not useful for describing systems that are not just architecturally, but also politically, decentralized. What if we have a system where we want to be fault-tolerant against some parts of the system misacting, but the parts of the system might be managed by different organizations or individuals, and you do not trust all of them not to be malicious (although you do trust that at least, say, two thirds of them will act honestly)? In this case, the model we want is Byzantine fault tolerance (named after the Byzantine Generals Problem) - most nodes will honestly follow the protocol, but some will deviate, and they can deviate in any way; the assumption is that all deviating nodes are colluding to screw you over. A Byzantine-fault-tolerant protocol should survive against a limited number of such deviations.
For an example of simple and Byzantine fault-tolerance in action, a good use case is decentralized file storage.
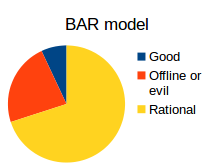
Beyond these two scenarios, there is also another even more sophisticated model: the Byzantine/Altruistic/Rational model. The BAR model improves upon the Byzantine model by adding a simple realization: in real life, there is no sharp distinction between "honest" and "dishonest" people; everyone is motivated by incentives, and if the incentives are high enough then even the majority of participants may well act dishonestly - particularly if the protocol in question weights people's influence by economic power, as pretty much all protocols do in the blockchain space. Thus, the BAR model assumes three types of actors:
- Altruistic - altruistic actors always follow the protocol
- Rational - rational actors follow the protocol if it suits them, and do not follow the protocol if it does not
- Byzantine - Byzantine actors are all conspiring to screw you over
In practice, protocol developers tend to be uncomfortable assuming any specific nonzero quantity of altruism, so the model that many protocols are judged by is the even harsher "BR" model; protocols that survive under BR are said to be incentive-compatible (anything that survives under BR survives under BAR, since an altruist is guaranteed to be at least as good for the health of the protocol as anyone else as benefitting the protocol is their explicit objective).
 |  |  |
To see how this model works, let us examine an argument for why Bitcoin is incentive-compatible. The part of Bitcoin that we care most about is the mining protocol, with miners being the users. The "correct" strategy defined in the protocol is to always mine on the block with the highest "score", where score is roughly defined as follows:
- If a block is the genesis block, score(B) = 0
- If a block is invalid, score(B) = -infinity
- Otherwise, score(B) = score(B.parent) + 1
In practice, the contribution that each block makes to the total score varies with difficulty, but we can ignore such subtleties in our simple analysis. If a block is successfully mined, then the miner receives a reward of 50 BTC. In this case, we can see that there are exactly three Byzantine strategies:
- Not mining at all
- Mining on a block other than the block with highest score
- Trying to produce an invalid block
The argument against (1) is simple: if you don't mine, you don't get the reward. Now, let's look at (2) and (3). If you follow the correct strategy, you have a probability p of producing a valid block with score s + 1 for some s. If you follow a Byzantine strategy, you have a probability p of producing a valid block with score q + 1 with q < s (and if you try to produce an invalid block, you have a probability of producing some block with score negative infinity). Thus, your block is not going to be the block with the highest score, so other miners are not going to mine on it, so your mining reward will not be part of the eventual longest chain. Note that this argument does not depend on altruism; it only depends on the idea that you have an incentive to keep in line if everyone else does - a classic Schelling point argument.
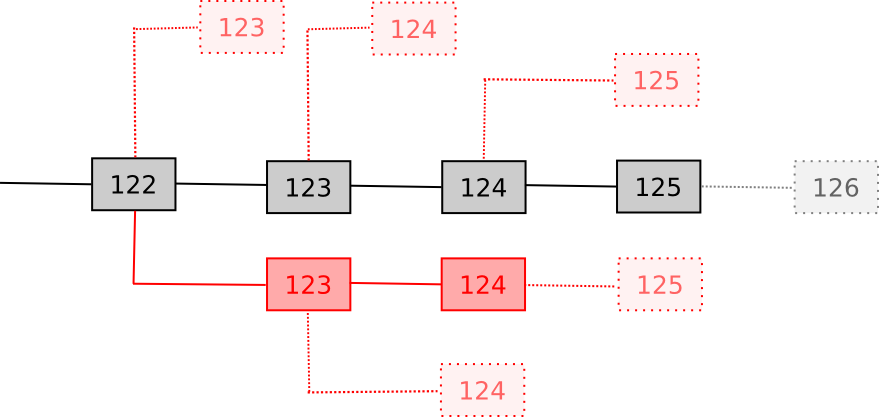
The best strategy to maximize the chance that your block will get included in the eventual winning blockchain is to mine on the block that has the highest score.
Trust-Free Systems
Another important category of cryptoeconomic protocols is the set of so-called "trust-free" centralized protocols. Of these, there are a few major categories:
Provably fair gambling
One of the big problems in online lotteries and gambling sites is the possibility of operator fraud, where the operator of the site would slightly and imperceptibly "load the dice" in their favor. A major benefit of cryptocurrency is its ability to remove this problem by constructing a gambling protocol that is auditable, so any such deviation can be very quickly detected. A rough outline of a provably fair gambling protocol is as follows:
- At the beginning of each day, the site generates a seed s and publishes H(s) where H is some standard hash function (eg. SHA3)
- When a user sends a transaction to make a bet, the "dice roll" is calculated using H(s + TX) mod n where TX is the transaction used to pay for the bet and n is the number of possible outcomes (eg. if it's a 6-sided die, n = 6, for a lottery with a 1 in 927 chance of winning, n = 927 and winning games are games where H(s + TX) mod 927 = 0).
- At the end of the day, the site publishes s.
Users can then verify that (1) the hash provided at the beginning of the day actually is H(s), and (2) that the results of the bets actually match the formulas. Thus, a gambling site following this protocol has no way of cheating without getting caught within 24 hours; as soon as it generates s and needs to publish a value H(s) it is basically bound to follow the precise protocol correctly.
Proof of Solvency
Another application of cryptography is the concept of creating auditable financial services (technically, gambling is a financial service, but here we are interested in services that hold your money, not just briefly manipulate it). There are strong theoretical arguments and empirical evidence that financial services of that sort are much more likely to try to cheat their users; perhaps the most parcticularly jarring example is the case of MtGox, a Bitcoin exchange which shut down with over 600,000 BTC of customer funds missing.
The idea behind proof of solvency is as follows. Suppose there is an exchange with users U[1] ... U[n] where user U[i] has balance b[i]. The sum of all balances is B. The exchange wants to prove that it actually has the bitcoins to cover everyone's balances. This is a two-part problem: the exchange must simultaneously prove that for some B it is true that (1) the sum of users' balances is B, and (ii) the exchange is in possession of at least B BTC. The second is easy to prove; just sign a message with the private key that holds the bitcoins at the time. The simplest way to prove the first is to just publish everyone's balances, and let people check that their balances match the public values, but this compromises privacy; hence, a better strategy is needed.
The solution involves, as usual, a Merkle tree - except in this case it's a funky enhanced sort of Merkle tree called a "Merkle sum tree". Instead of each node simply being the hash of its children, every node contains the hash of its children and the sum of the values of its children:
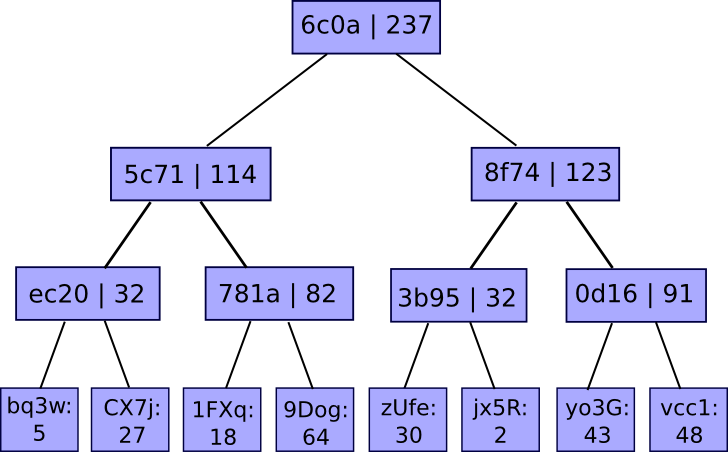
The values at the bottom are mappings of account IDs to balances. The service publishes the root of the tree, and if a user wants a proof that their account is correctly included in the tree, the service can simply give them the branch of the tree corresponding to their account:
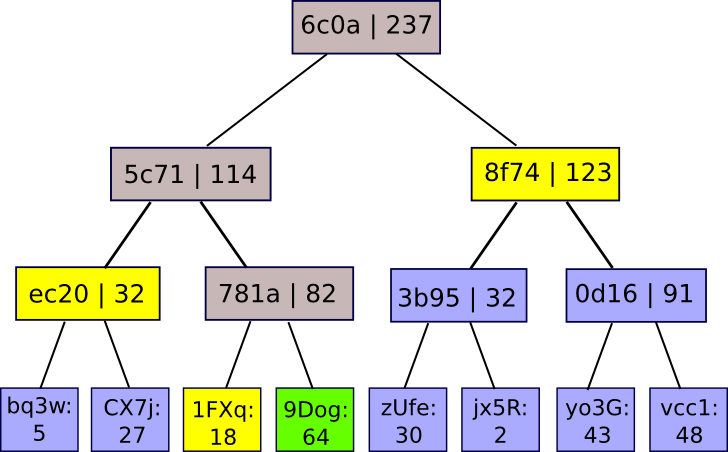
There are two ways that the site can cheat, and try to get away with having a fractional reserve. First, it can try to have one of the nodes in the Merkle tree incorrectly sum the values of its children. In this case, as soon as a user requests a branch containing that node they will know that something is wrong. Second, it can try to insert negative values into the leaves of the tree. However, if it does this, then unless the site provides fake positive and negative nodes that cancel each other out (thus defeating the whole point), then there will be at least one legitimate user whose Merkle branch will contain the negative value; in general, getting away with having X percent less than the required reserve requires counting on a specific X percent of users never performing the audit procedure - a result that is actually the best that any protocol can do, given that an exchange can always simply zero out some percentage of its users' account balances if it knows that they will never discover the fraud.
Multisig
A third application, and a very important one, is multisig, or more generally the concept of multi-key authorization. Instead of your account being controlled by one private key which may get hacked, there are three keys, of which two are needed to access the account (or some other configuration, perhaps involving withdrawal limits or time-locked withdrawals; Bitcoin does not support such features but more advanced systems do). The way multisig is usually implemented so far is as a 2-of-3: you have one key, the server has one key, and you have a third backup key in a safe place. In the course of normal activity, when you sign a transaction you generally sign it with your key locally, then send it to the server. The server performs some second verification process - perhaps consisting of sending a confirmation code to your phone, and if it confirms that you meant to send the transaction then it signs it as well.
The idea is that such a system is tolerant against any single fault, including any single Byzantine fault. If you lose your password, you have a backup, which together with the server can recover your funds, and if your password is hacked, the attacker only has one password; likewise for loss or theft of the backup. If the service disappears, you have two keys. If the service is hacked or turns out to be evil, it only has one. The probability of two failures happening at the same time is very small; arguably, you are more likely to die.
Fundamental Units
All of the above arguments make one key assumption that seems trivial, but actually needs to be challenged much more closely: that the fundamental unit of the system is the computer. Each node has the incentive to mine on the block with the highest score and not follow some deviant strategy. If the server gets hacked in a multisig then your computer and your backup still have 2 out of 3 keys, so you are still safe. The problem with the approach is that it implicitly assumes that users have full control over their computers, and that the users fully understand cryptography and are manually verifying the Merkle tree branches. In reality, this is not the case; in fact, the very necessity of multisig in any incarnation at all is proof of this, as it acknowledges that users' computers can get hacked - a replica of the behavioral-economics idea that individuals can be viewed as not being in full control of themselves.
A more accurate model is to view a node as a combination of two categories of agents: a user, and one or more software providers. Users in nearly all cases do not verify their software; even in my own case, even though I verify every transaction that comes out of the Ethereum exodus address, using the pybitcointools toolkit that I wrote from scratch myself (others have provided patches, but even those I reviewed personally), I am still trusting that (1) the implementations of Python and Ubuntu that I downloaded are legitimate, and (2) that the hardware is not somehow bugged. Hence, these software providers should be treated as separate entities, and their goals and incentives should be analyzed as actors in their own right. Meanwhile, users should also be viewed as agents, but as agents who have limited technical capability, and whose choice set often simply consists of which software packages to install, and not precisely which protocol rules to follow.
The first, and most important, observation is that the concepts of "Byzantine fault tolerance" and "single point of failure" should be viewed in light of such a distinction. In theory, multisig removes all single points of failure from the cryptographic token management process. In practice, however, that is not the way that multisig is usually presented. Right now, most mainstream multisig wallets are web applications, and the entity providing the web application is the same entity that manages the backup signing key. What this means is that, if the wallet provider does get hacked or does turn out to be evil, they actually have control over two out of three keys - they already have the first one, and can easily grab the second one simply by making a small change to the client-side browser application they send to you every time you load the webpage.
In multisig wallet providers' defense, services like BitGo and GreenAddress do offer an API, allowing developers to use their key management functionality without their interface so that the two providers can be separate entities. However, the importance of this kind of separation is currently drastically underemphasized.
This insight applies equally well to provably fair gambling and proof of solvency. Particular, such provably fair protocols should have standard implementations, with open-source applications that can verify proofs in a standard format and in a way that is easy to use. Services like exchanges should then follow those protocols, and deliver proofs which can be verifies by these external tools. If a service releases a proof that can only be verified by its own internal tools, that is not much better than no proof at all - slightly better, since there is a chance that cheating will still be detected, but not by much.
Software, Users and Protocols
If we actually do have two classes of entities, it will be helpful to provide at least a rough model of their incentives, so that we may better understand how they are likely to act. In general, from software providers we can roughly expect the following goals:
- Maximize profit - in the heyday of proprietary software licensing, this goal was actually easy to understand: software companies maximize their profits by having as many users as possible. The drive toward open-source and free-to-use software more recently has very many advantages, but one disadvantage is that it now makes the profit-maximization analysis much more difficult. Now, software companies generally make money through commercial value-adds, the defensibility of which typically involves creating proprietary walled-garden ecosystems. Even still, however, making one's software as useful as possible usually helps, at least when it doesn't interfere with a proprietary value-add.
- Altruism - altruists write software to help people, or to help realize some vision of the world.
- Maximize reputation - these days, writing open-source software is often used as a way of building up one's resume, so as to (1) appear more attractive to employers and (2) gain the social connections to maximize potential future opportunities. Corporations can also do this, writing free tools to drive people to their website in order to promote other tools.
- Laziness - software providers will not write code if they can help it. The main consequence of this will be an underinvestment in features that do not benefit their users, but benefit the ecosystem - like responding to requests for data - unless the software ecosystem is an oligopoly.
- Not going to jail - this entails compliance with laws, which sometimes involves anti-features such as requiring identity verification, but the dominant effect of this motive is a disincentive against screwing one's customers over too blatantly (eg. stealing their funds).
Users we will not analyze in terms of goals but rather in terms of a behavioral model: users select software packages from an available set, download the software, and choose options from inside that software. Guiding factors in software selection include:
- Functionality - what is the utility (that's the economics jargon "utility") can they derive from the options that the software provides?
- Ease of use - of particular importance is the question of how quickly they can get up and running doing what they need to do.
- Perceived legitimacy - users are more likely to download software from trustworthy or at least trustworthy-seeming entities.
- Salience - if a software package is mentioned more often, users will be more likely to go for it. An immediate consequence is that the "official" version of a software package has a large advantage over any forks.
- Moral and ideological considerations - users might prefer open source software for its own sake, reject purely parasitic forks, etc.
Once users download a piece of software, the main bias that we can count on is that users will stick to defaults even when it might not benefit them to; beyond that, we have more traditional biases such as loss aversion, which we will discuss briefly later.
Now, let us show an example of how this process works in action: BitTorrent. In the BitTorrent protocol, users can download files from each other a packet at a time in a decentralized fashion, but in order for one user to download a file there must be someone uploading ("seeding") it - and that activity is not incentivized. In fact, it carries non-negligible costs: bandwidth consumption, CPU resource consumption, copyright-related legal risk (including risk of getting one's internet connection shut down by one's ISP, or perhaps even a possibility of lawsuit). And yet people still seed - vastly insufficiently, but they do.
Why? The situation is explained perfectly by the two-layer model: software providers want to make their software more useful, so they include the seeding functionality by default, and users are too lazy to turn it off (and some users are deliberately altruistic, though the order-of-magnitude mismatch between willingness to torrent copyrighted content and willingness to donate to artists does suggest that most participants don't really care). Message-sending in Bitcoin (ie. to data requests like getblockheader and getrawtransaction) is also altruistic but also similarly explainable, as is the inconsistency between transaction fees and what the economics suggest transaction fees currently should be.
Another example is proof of stake algorithms. Proof of stake algorithms have the (mostly) common vulnerability that there is "nothing at stake" - that is to say, that the default behavior in the event of a fork is to try to vote on all chains, so an attacker need only overpower all altruists that vote on one chain only, and not all altruists plus all rational actors as in the case of proof of work. Here, once again we can see that this does not mean that proof of stake is completely broken. If the stake is largely controlled by a smaller number of sophisticated parties, then those parties will have their ownership in the currency as the incentive not to participate in forks, and if the stake is controlled by very many more ordinary people then there would need to be some deliberately evil software provider who would take an effort to include a multi-voting feature, and advertise it so that potentially users actually know about the feature.
However, if the stake is held in custodial wallets (eg. Coinbase, Xapo, etc) which do not legally own the coins, but are specialized professional entities, then this argument breaks down: they have the technical ability to multi-vote, and low incentive not to, particularly if their businesses are not "Bitcoin-centric" (or Ethereum-centric, or Ripple-cetric) and support many protocols. There is even a probabilistic multi-voting strategy which such custodial entities can use to get 99% of the benefits of multi-voting without the risk of getting caught. Hence, effective proof of stake to a moderate extent depends on technologies that allow users to safely keep control of their own coins.
Darker Consequences
What we get out of the default effect is essentially a certain level of centralization, having a beneficial role by setting users' default behavior toward a socially beneficial action and thereby correcting for what would otherwise be a market failure. Now, if software introduces some benefits of centralization, we can also expect some of the negative effects of centralization as well. One particular example is fragility. Theoretically, Bitcoin mining is an M-of-N protocol where N is in the thousands; if you do the combinatoric math, the probability that even 5% of the nodes will deviate from the protocol is infinitesimally small, so Bitcoin should have pretty much perfect reliability. In reality, of course, this is incorrect; Bitcoin has had no less than two outages in the last six years.
For those who do not remember, the two cases were as follows:
 Driver of 43-year-old car exploits integer overflow vulnerability, sells it for 91% of original purchase price passing it off as new
Driver of 43-year-old car exploits integer overflow vulnerability, sells it for 91% of original purchase price passing it off as new
- In 2010, an unknown user created a transaction with two outputs, each containing slightly more than 263 satoshis. The two outputs combined were slightly over 264, and integer overflow led to the total wrapping around to near-zero, causing the Bitcoin client to think that the transaction actually released only the same small quantity of BTC that it consumed as an input, and so was legitimate. The bug was fixed, and the blockchain reverted, after nine hours.
- In 2013, a new version of the Bitcoin client unknowingly fixed a bug in which a block that made over 5000 accesses to a certain database resource would cause a BerkeleyDB error, leading to the client rejecting the block. Such a block soon appeared, and new clients accepted it and old clients rejected it, leading to a fork. The fork was fixed in six hours, but in the meantime $10000 of BTC was stolen from a payment service provider in a double-spend attack.
In both cases, the network was only able to fail because, even though there were thousands of nodes, there was only one software implementation running them all - perhaps the ultimate fragility in a network that is often touted for being antifragile. Alternative implementations such as btcd are now increasingly being used, but it will be years before Bitcoin Core's monopoly is anything close to broken; and even then fragility will still be fairly high.
Endowment effects and Defaults
An important set of biases to keep in mind on the user side are the concepts of the endowment effect, loss aversion, and the default effect. The three often go hand in hand, but are somewhat different from each other. The default effect is generally most accurately modeled as a tendency to continue following one's current strategy unless there is a substantial benefit to switching - in essence, an artificial psychological switching cost of some value ε. The endowment effect is the tendency to see things as being more valuable if one already has them, and loss aversion is the tendency to care more about avoiding losses than seeking gains - experimentally, the scaling factor seems to be consistently around 2x.
The consequences of these effects pronounce themselves most strongly in the context of multi-currency environments. As one example, consider the case of employees being paid in BTC. We can see that when people are paid in BTC, they are much more likely to hold on to those BTC than they would have been likely to buy the BTC had they been paid USD; the reason is partially the default effect, and partially the fact that if someone is paid in BTC they "think in BTC" so if they sell to USD then if the value of BTC goes up after that they have a risk of suffering a loss, whereas if someone is paid in USD it is the USD-value of their BTC that they are more concerned with. This applies also to smaller token systems; if you pay someone in Zetacoin, they are likely to cash out into BTC or some other coin, but the probability is much less than 100%.
The loss aversion and default effects are some of the strongest arguments in favor of the thesis that a highly polycentric currency system is likely to continue to survive, contra Daniel Krawisz's viewpoint that BTC is the one token to rule them all. There is clearly an incentive for software developers to create their own coin even if the protocol could work just as well on top of an existing currency: you can do a token sale. StorJ is the latest example of this. However, as Daniel Krawisz argues, one could simply fork such an "app-coin" and release a version on top of Bitcoin, which would theoretically be superior because Bitcoin is a more liquid asset to store one's funds in. The reason why such an outcome has a large chance of not happening is simply the fact that users follow defaults, and by default users will use StorJ with StorJcoin since that is what the client will promote, and the original StorJ client and website and ecosystem is the one that will get all the attention.
Now, this argument breaks down somewhat in one case: if the fork is itself backed by a powerful entity. The latest example of this is the case of Ripple and Stellar; although Stellar is a fork of Ripple, it is backed by a large company, Stripe, so the fact that the original version of a software package has the advantage of much greater salience does not apply quite as strongly. In such cases, we do not really know what will happen; perhaps, as is often the case in the social sciences, we will simply have to wait for empirical evidence to find out.
The Way Forward
Relying on specific psychological features of humans in cryptographic protocol design is a dangerous game. The reason why it is good in economics to keep one's model simple, and in cryptoeconomics even more so, is that even if desires like the desire to acquire more currency units do not accurately describe the whole of human motivation, they describe an evidently very powerful component of it, and some may argue the only powerful component we can count on. In the future, education may begin to deliberately attack what we know as psychological irregularities (in fact, it already does), changing culture may lead to changing morals and ideals, and particularly in this case the agents we are dealing with are "fyborgs" - functional cyborgs, or humans who have all of their actions mediated by machines like the one that sits between them and the internet.
However, there are certain fundamental features of this model - the concept of cryptoeconomic systems as two-layer systems featuring software and users as agents, the preference for simplicity, etc, that perhaps can be counted on, and at the very least we should try to be aware of circumstances where our protocol is secure under the BAR model, but insecure under the model where a few centralized parties are in practice mediating everyone's access to the system. The model also highlights the importance of "software politics" - having an understanding of the pressures that drive software development, and attempting to come up with approaches to development that software developers have the best possible incentives (or, ultimately, write software that is most favorable to the protocol's successful execution). These are problems that Bitcoin has not solved, and that Ethereum has not solved; perhaps some future system will do at least somewhat better.