


An important and controversial topic in the area of personal wallet security is the concept of "brainwallets" - storing funds using a private key generated from a password memorized entirely in one's head. Theoretically, brainwallets have the potential to provide almost utopian guarantee of security for long-term savings: for as long as they are kept unused, they are not vulnerable to physical theft or hacks of any kind, and there is no way to even prove that you still remember the wallet; they are as safe as your very own human mind. At the same time, however, many have argued against the use of brainwallets, claiming that the human mind is fragile and not well designed for producing, or remembering, long and fragile cryptographic secrets, and so they are too dangerous to work in reality. Which side is right? Is our memory sufficiently robust to protect our private keys, is it too weak, or is perhaps a third and more interesting possibility actually the case: that it all depends on how the brainwallets are produced?
Entropy
If the challenge at hand is to create a brainwallet that is simultaneously memorable and secure, then there are two variables that we need to worry about: how much information we have to remember, and how long the password takes for an attacker to crack. As it turns out, the challenge in the problem lies in the fact that the two variables are very highly correlated; in fact, absent a few certain specific kinds of special tricks and assuming an attacker running an optimal algorithm, they are precisely equivalent (or rather, one is precisely exponential in the other). However, to start off we can tackle the two sides of the problem separately.
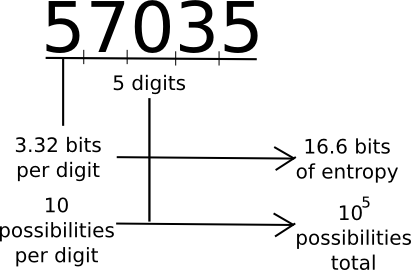
A common measure that computer scientists, cryptogaphers and mathematicians use to measure "how much information" a piece of data contains is "entropy". Loosely defined, entropy is defined as the logarithm of the number of possible messages that are of the same "form" as a given message. For example, consider the number 57035. 57035 seems to be in the category of five-digit numbers, of which there are 100000. Hence, the number contains about 16.6 bits of entropy, as 216.6 ~= 100000. The number 61724671282457125412459172541251277 is 35 digits long, and log(1035) ~= 116.3, so it has 116.3 bits of entropy. A random string of ones and zeroes n bits long will contain exactly n bits of entropy. Thus, longer strings have more entropy, and strings that have more symbols to choose from have more entropy.
On the other hand, the number 11111111111111111111111111234567890 has much less than 116.3 bits of entropy; although it has 35 digits, the number is not of the category of 35-digit numbers, it is in the category of 35-digit numbers with a very high level of structure; a complete list of numbers with at least that level of structure might be at most a few billion entries long, giving it perhaps only 30 bits of entropy.
Information theory has a number of more formal definitions that try to grasp this intuitive concept. A particularly popular one is the idea of Kolmogorov complexity; the Kolmogorov complexity of a string is basically the length of the shortest computer program that will print that value. In Python, the above string is also expressible as '1'*26+'234567890' - an 18-character string, while 61724671282457125412459172541251277 takes 37 characters (the actual digits plus quotes). This gives us a more formal understanding of the idea of "category of strings with high structure" - those strings are simply the set of strings that take a small amount of data to express. Note that there are other compression strategies we can use; for example, unbalanced strings like 1112111111112211111111111111111112111 can be cut by at least half by creating special symbols that represent multiple 1s in sequence. Huffman coding is an example of an information-theoretically optimal algorithm for creating such transformations.
Finally, note that entropy is context-dependent. The string "the quick brown fox jumped over the lazy dog" may have over 100 bytes of entropy as a simple Huffman-coded sequence of characters, but because we know English, and because so many thousands of information theory articles and papers have already used that exact phrase, the actual entropy is perhaps around 25 bytes - I might refer to it as "fox dog phrase" and using Google you can figure out what it is.
So what is the point of entropy? Essentially, entropy is how much information you have to memorize. The more entropy it has, the harder to memorize it is. Thus, at first glance it seems that you want passwords that are as low-entropy as possible, while at the same time being hard to crack. However, as we will see below this way of thinking is rather dangerous.
Strength
Now, let us get to the next point, password security against attackers. The security of a password is best measured by the expected number of computational steps that it would take for an attacker to guess your password. For randomly generated passwords, the simplest algorithm to use is brute force: try all possible one-character passwords, then all two-character passwords, and so forth. Given an alphabet of n characters and a password of length k, such an algorithm would crack the password in roughly nk time. Hence, the more characters you use, the better, and the longer your password is, the better.
There is one approach that tries to elegantly combine these two strategies without being too hard to memorize: Steve Gibson's haystack passwords. As Steve Gibson explains:
Which of the following two passwords is stronger, more secure, and more difficult to crack?
You probably know this is a trick question, but the answer is: Despite the fact that the first password is HUGELY easier to use and more memorable, it is also the stronger of the two! In fact, since it is one character longer and contains uppercase, lowercase, a number and special characters, that first password would take an attacker approximately 95 times longer to find by searching than the second impossible-to-remember-or-type password!
Steve then goes on to write: "Virtually everyone has always believed or been told that passwords derived their strength from having “high entropy”. But as we see now, when the only available attack is guessing, that long-standing common wisdom . . . is . . . not . . . correct!" However, as seductive as such a loophole is, unfortunately in this regard he is dead wrong. The reason is that it relies on specific properties of attacks that are commonly in use, and if it becomes widely used attacks could easily emerge that are specialized against it. In fact, there is a generalized attack that, given enough leaked password samples, can automatically update itself to handle almost anything: Markov chain samplers.
The way the algorithm works is as follows. Suppose that the alphabet that you have consists only of the characters 0 and 1, and you know from sampling that a 0 is followed by a 1 65% of the time and a 0 35% of the time, and a 1 is followed by a 0 20% of the time and a 1 80% of the time. To randomly sample the set, we create a finite state machine containing these probabilities, and simply run it over and over again in a loop.
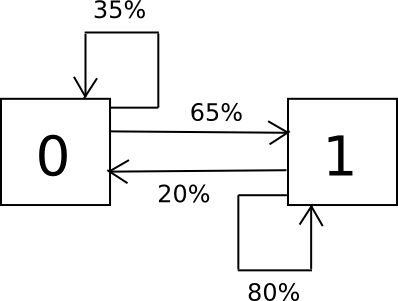
Here's the Python code:
import random i = 0 while 1: if i == 0: i = 0 if random.randrange(100) < 35 else 1 elif i == 1: i = 0 if random.randrange(100) < 20 else 1 print i
We take the output, break it up into pieces, and there we have a way of generating passwords that have the same pattern as passwords that people actually use. We can generalize this past two characters to a complete alphabet, and we can even have the state keep track not just of the last character but the last two, or three or more. So if everyone starts making passwords like "D0g.....................", then after seeing a few thousand examples the Markov chain will "learn" that people often make long strings of periods, and if it spits out a period it will often get itself temporarily stuck in a loop of printing out more periods for a few steps - probabilistically replicating people's behavior.
The one part that was left out is how to terminate the loop; as given, the code simply gives an infinite string of zeroes and ones. We could introduce a pseudo-symbol into our alphabet to represent the end of a string, and incorporate the observed rate of occurrences of that symbol into our Markov chain probabilities, but that's not optimal for this use case - because far more passwords are short than long, it would usually output passwords that are very short, and so it would repeat the short passwords millions of times before trying most of the long ones. Thus we might want to artificially cut it off at some length, and increase that length over time, although more advanced strategies also exist like running a simultaneous Markov chain backwards. This general category of method is usually called a "language model" - a probability distribution over sequences of characters or words which can be as simple and rough or as complex and intricate as needed, and which can then be sampled.
The fundamental reason why the Gibson strategy fails, and why no other strategy of that kind can possibly work, is that in the definitions of entropy and strength there is an interesting equivalence: entropy is the logarithm of the number of possibilities, but strength is the number of possibilities - in short, memorizability and attackability are invariably exactly the same! This applies regardless of whether you are randomly selecting characters from an alphabet, words from a dictionary, characters from a biased alphabet (eg. "1" 80% of the time and "0" 20% of the time, or strings that follow a particular pattern). Thus, it seems that the quest for a secure and memorizable password is hopeless...
Easing Memory, Hardening Attacks
... or not. Although the basic idea that entropy that needs to be memorized and the space that an attacker needs to burn through are exactly the same is mathematically and computationally correct, the problem lives in the real world, and in the real world there are a number of complexities that we can exploit to shift the equation to our advantage.
The first important point is that human memory is not a computer-like store of data; the extent to which you can accurately remember information often depends on how you memorize it, and in what format you store it. For example, we implicitly memorize kilobytes of information fairly easily in the form of human faces, but even something as similar in the grand scheme of things as dog faces are much harder for us. Information in the form of text is even harder - although if we memorize the text visually and orally at the same time it's somewhat easier again.
Some have tried to take advantage of this fact by generating random brainwallets and encoding them in a sequence of words; for example, one might see something like:
witch collapse practice feed shame open despair creek road again ice least
A popular XKCD comic illustrates the principle, suggesting that users create passwords by generating four random words instead of trying to be clever with symbol manipulation. The approach seems elegant, and perhaps taking away of our differing ability to remember random symbols and language in this way, it just might work. Except, there's a problem: it doesn't.
To quote a recent study by Richard Shay and others from Carnegie Mellon:
In a 1,476-participant online study, we explored the usability of 3- and 4-word system- assigned passphrases in comparison to system-assigned passwords composed of 5 to 6 random characters, and 8-character system-assigned pronounceable passwords. Contrary to expectations, sys- tem-assigned passphrases performed similarly to system-assigned passwords of similar entropy across the usability metrics we ex- amined. Passphrases and passwords were forgotten at similar rates, led to similar levels of user difficulty and annoyance, and were both written down by a majority of participants. However, passphrases took significantly longer for participants to enter, and appear to require error-correction to counteract entry mistakes. Passphrase usability did not seem to increase when we shrunk the dictionary from which words were chosen, reduced the number of words in a passphrase, or allowed users to change the order of words.
However, the paper does leave off on a note of hope. It does note that there are ways to make passwords that are higher entropy, and thus higher security, while still being just as easy to memorize; randomly generated but pronounceable strings like "zelactudet" (presumably created via some kind of per-character language model sampling) seem to provide a moderate gain over both word lists and randomly generated character strings. A likely cause of this is that pronounceable passwords are likely to be memorized both as a sound and as a sequence of letters, increasing redundancy. Thus, we have at least one strategy for improving memorizability without sacrificing strength.
The other strategy is to attack the problem from the opposite end: make it harder to crack the password without increasing entropy. We cannot make the password harder to crack by adding more combinations, as that would increase entropy, but what we can do is use what is known as a hard key derivation function. For example, suppose that if our memorized brainwallet is b, instead of making the private key sha256(b) or sha3(b), we make it F(b, 1000) where F is defined as follows:
def F(b, rounds): x = b i = 0 while i < rounds: x = sha3(x + b) i += 1 return x
Essentially, we keep feeding b into the hash function over and over again, and only after 1000 rounds do we take the output.

Feeding the original input back into each round is not strictly necessary, but cryptographers recommend it in order to limit the effect of attacks involving precomputed rainbow tables. Now, checking each individual password takes a thousand time longer. You, as the legitimate user, won't notice the difference - it's 20 milliseconds instead of 20 microseconds - but against attackers you get ten bits of entropy for free, without having to memorize anything more. If you go up to 30000 rounds you get fifteen bits of entropy, but then calculating the password takes close to a second; 20 bits takes 20 seconds, and beyond about 23 it becomes too long to be practical.
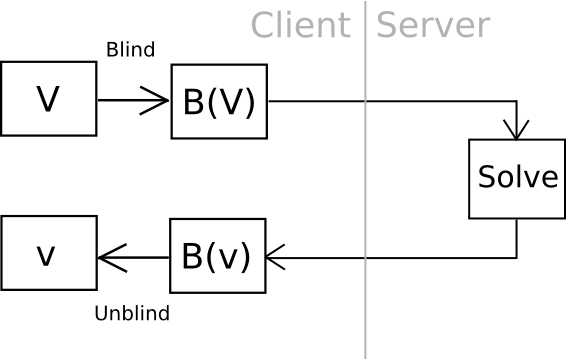
Now, there is one clever way we can go even further: outsourceable ultra-expensive KDFs. The idea is to come up with a function which is extremely expensive to compute (eg. 240 computational steps), but which can be computed in some way without giving the entity computing the function access to the output. The cleanest, but most cryptographically complicated, way of doing this is to have a function which can somehow be "blinded" so unblind(F(blind(x))) = F(x) and blinding and unblinding requires a one-time randomly generated secret. You then calculate blind(password), and ship the work off to a third party, ideally with an ASIC, and then unblind the response when you receive it.
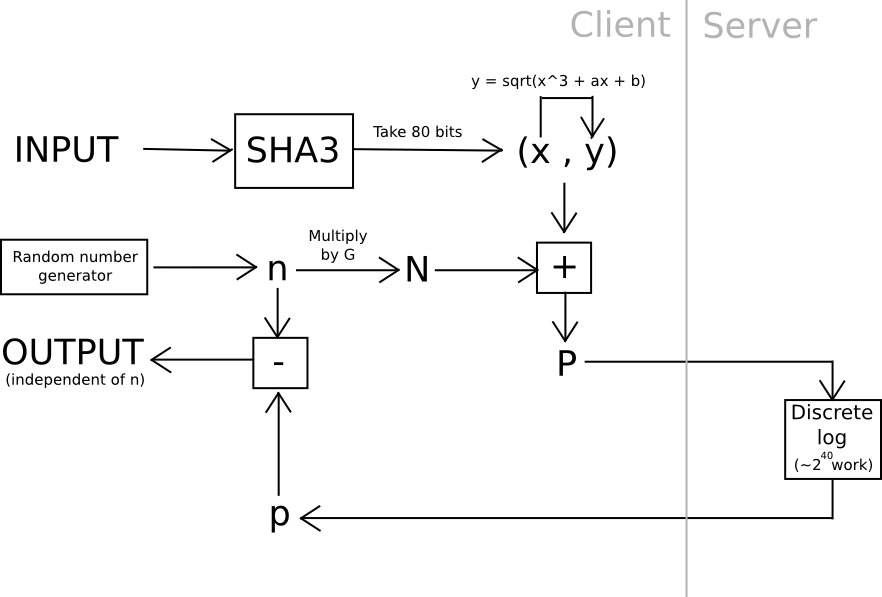
One example of this is using elliptic curve cryptography: generate a weak curve where the values are only 80 bits long instead of 256, and make the hard problem a discrete logarithm computation. That is, we calculate a value x by taking the hash of a value, find the associated y on the curve, then we "blind" the (x,y) point by adding another randomly generated point, N (whose associated private key we know to be n), and then ship the result off to a server to crack. Once the server comes up with the private key corresponding to N + (x,y), we subtract n, and we get the private key corresponding to (x,y) - our intended result. The server does not learn any information about what this value, or even (x,y), is - theoretically it could be anything with the right blinding factor N. Also, note that the user can instantly verify the work - simply convert the private key you get back into a point, and make sure that the point is actually (x,y).
Another approach relies somewhat less on algebraic features of nonstandard and deliberately weak elliptic curves: use hashes to derive 20 seeds from a password, apply a very hard proof of work problem to each one (eg. calculate f(h) = n where n is such that sha3(n+h) < 2^216), and combine the values using a moderately hard KDF at the end. Unless all 20 servers collude (which can be avoided if the user connects through Tor, since it would be impossible even for an attacker controlling or seeing the results of 100% of the network to determine which requests are coming from the same user), the protocol is secure.
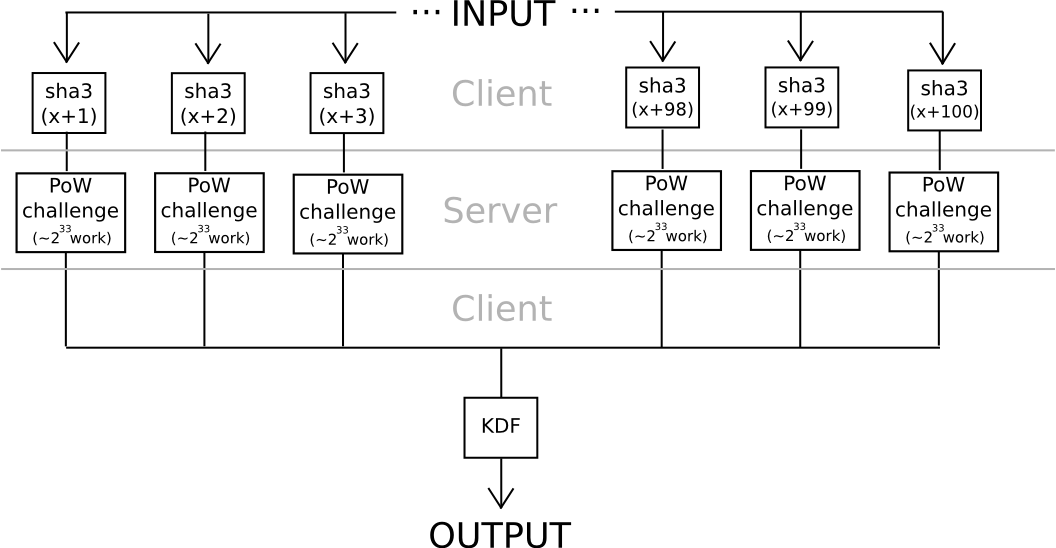
The interesting thing about both of these protocols is that they are fairly easy to turn into a "useful proof of work" consensus algorithm for a blockchain; anyone could submit work for the chain to process, the chain would perform the computations, and both elliptic curve discrete logs and hash-based proofs of work are very easy to verify. The elegant part of the scheme is that it turns to social use both users' expenses in computing the work function, but also attackers' much greater expenses. If the blockchain subsidized the proof of work, then it would be optimal for attackers to also try to crack users' passwords by submitting work to the blockchain, in which case the attackers would contribute to the consensus security in the process. But then, in reality at this level of security, where 240 work is needed to compute a single password, brainwallets and other passwords would be so secure that no one would even bother attacking them.
Entropy Differentials
Now, we get to our final, and most interesting, memorization strategy. From what we discussed above, we know that entropy, the amount of information in a message, and the complexity of attack are exactly identical - unless you make the process deliberately slower with expensive KDFs. However, there is another point about entropy that was mentioned in passing, and which is actually crucial: experienced entropy is context-dependent. The name "Mahmoud Ahmadjinejad" might have perhaps ten to fifteen bits of entropy to us, but to someone living in Iran while he was president it might have only four bits - in the list of the most important people in their lives, he is quite likely in the top sixteen. Your parents or spouse are completely unknown to myself, and so for me their names have perhaps twenty bits of entropy, but to you they have only two or three bits.
Why does this happen? Formally, the best way to think about it is that for each person the prior experiences of their lives create a kind of compression algorithm, and under different compression algorithms, or different programming languages, the same string can have a different Kolmogorov complexity. In Python, '111111111111111111' is just '1'*18, but in Javascript it's Array(19).join("1"). In a hypothetical version of Python with the variable x preset to '111111111111111111', it's just x. The last example, although seemingly contrived, is actually the one that best describes much of the real world; the human mind is a machine with many variables preset by our past experiences.
This rather simple insight leads to a particularly elegant strategy for password memorizability: try to create a password where the "entropy differential", the difference between the entropy to you and the entropy to other people, is as large as possible. One simple strategy is to prepend your own username to the password. If my password were to be "yui&(4_", I might do "vbuterin:yui&(4_" instead. My username might have about ten to fifteen bits of entropy to the rest of the world, but to me it's almost a single bit. This is essentially the primary reason why usernames exist as an account protection mechanism alongside passwords even in cases where the concept of users having "names" is not strictly necessary.
Now, we can go a bit further. One common piece of advice that is now commonly and universally derided as worthless is to pick a password by taking a phrase out of a book or song. The reason why this idea is seductive is because it seems to cleverly exploit differentials: the phrase might have over 100 bits of entropy, but you only need to remember the book and the page and line number. The problem is, of course, that everyone else has access to the books as well, and they can simply do a brute force attack over all books, songs and movies using that information.
However, the advice is not worthless; in fact, if used as only part of your password, a quote from a book, song or movie is an excellent ingredient. Why? Simple: it creates a differential. Your favorite line from your favorite song only has a few bits of entropy to you, but it's not everyone's favorite song, so to the entire world it might have ten or twenty bits of entropy. The optimal strategy is thus to pick a book or song that you really like, but which is also maximally obscure - push your entropy down, and others' entropy higher. And then, of course, prepend your username and append some random characters (perhaps even a random pronounceable "word" like "zelactudet"), and use a secure KDF.
Conclusion
How much entropy do you need to be secure? Right now, password cracking chips can perform about 236 attempts per second, and Bitcoin miners can perform roughly 240 hashes per second (that's 1 terahash). The entire Bitcoin network together does 250 petahashes, or about 257 hashes per second. Cryptographers generally consider 280 to be an acceptable minimum level of security. To get 80 bits of entropy, you need either about 17 random letters of the alphabet, or 12 random letters, numbers and symbols. However, we can shave quite a bit off the requirement: fifteen bits for a username, fifteen bits for a good KDF, perhaps ten bits for an abbreviation from a passage from a semi-obscure song or book that you like, and then 40 more bits of plan old simple randomness. If you're not using a good KDF, then feel free to use other ingredients.
It has become rather popular among security experts to dismiss passwords as being fundamentally insecure, and argue for password schemes to be replaced outright. A common argument is that because of Moore's law attackers' power increases by one bit of entropy every two years, so you will have to keep on memorizing more and more to remain secure. However, this is not quite correct. If you use a hard KDF, Moore's law allows you to take away bits from the attacker's power just as quickly as the attacker gains power, and the fact that schemes such as those described above, with the exception of KDFs (the moderate kind, not the outsourceable kind), have not even been tried suggests that there is still some way to go. On the whole, passwords thus remain as secure as they have ever been, and remain very useful as one ingredient of a strong security policy - just not the only ingredient. Moderate approaches that use a combination of hardware wallets, trusted third parties and brainwallets may even be what wins out in the end.