


Proof of stake continues to be one of the most controversial discussions in the cryptocurrency space. Although the idea has many undeniable benefits, including efficiency, a larger security margin and future-proof immunity to hardware centralization concerns, proof of stake algorithms tend to be substantially more complex than proof of work-based alternatives, and there is a large amount of skepticism that proof of stake can work at all, particularly with regard to the supposedly fundamental "nothing at stake" problem. As it turns out, however, the problems are solvable, and one can make a rigorous argument that proof of stake, with all its benefits, can be made to be successful - but at a moderate cost. The purpose of this post will be to explain exactly what this cost is, and how its impact can be minimized.
Economic Sets and Nothing at Stake
First, an introduction. The purpose of a consensus algorithm, in general, is to allow for the secure updating of a state according to some specific state transition rules, where the right to perform the state transitions is distributed among some economic set. An economic set is a set of users which can be given the right to collectively perform transitions via some algorithm, and the important property that the economic set used for consensus needs to have is that it must be securely decentralized - meaning that no single actor, or colluding set of actors, can take up the majority of the set, even if the actor has a fairly large amount of capital and financial incentive. So far, we know of three securely decentralized economic sets, and each economic set corresponds to a set of consensus algorithms:
- Owners of computing power: standard proof of work, or TaPoW. Note that this comes in specialized hardware, and (hopefully) general-purpose hardware variants.
- Stakeholders: all of the many variants of proof of stake
- A user's social network: Ripple/Stellar-style consensus
Note that there have been some recent attempts to develop consensus algorithms based on traditional Byzantine fault tolerance theory; however, all such approaches are based on an M-of-N security model, and the concept of "Byzantine fault tolerance" by itself still leaves open the question of which set the N should be sampled from. In most cases, the set used is stakeholders, so we will treat such neo-BFT paradigms are simply being clever subcategories of "proof of stake".
Proof of work has a nice property that makes it much simpler to design effective algorithms for it: participation in the economic set requires the consumption of a resource external to the system. This means that, when contributing one's work to the blockchain, a miner must make the choice of which of all possible forks to contribute to (or whether to try to start a new fork), and the different options are mutually exclusive. Double-voting, including double-voting where the second vote is made many years after the first, is unprofitablem since it requires you to split your mining power among the different votes; the dominant strategy is always to put your mining power exclusively on the fork that you think is most likely to win.

With proof of stake, however, the situation is different. Although inclusion into the economic set may be costly (although as we will see it not always is), voting is free. This means that "naive proof of stake" algorithms, which simply try to copy proof of work by making every coin a "simulated mining rig" with a certain chance per second of making the account that owns it usable for signing a block, have a fatal flaw: if there are multiple forks, the optimal strategy is to vote on all forks at once. This is the core of "nothing at stake".

Note that there is one argument for why it might not make sense for a user to vote on one fork in a proof-of-stake environment: "altruism-prime". Altruism-prime is essentially the combination of actual altruism (on the part of users or software developers), expressed both as a direct concern for the welfare of others and the network and a psychological moral disincentive against doing something that is obviously evil (double-voting), as well as the "fake altruism" that occurs because holders of coins have a desire not to see the value of their coins go down.
Unfortunately, altruism-prime cannot be relied on exclusively, because the value of coins arising from protocol integrity is a public good and will thus be undersupplied (eg. if there are 1000 stakeholders, and each of their activity has a 1% chance of being "pivotal" in contributing to a successful attack that will knock coin value down to zero, then each stakeholder will accept a bribe equal to only 1% of their holdings). In the case of a distribution equivalent to the Ethereum genesis block, depending on how you estimate the probability of each user being pivotal, the required quantity of bribes would be equal to somewhere between 0.3% and 8.6% of total stake (or even less if an attack is nonfatal to the currency). However, altruism-prime is still an important concept that algorithm designers should keep in mind, so as to take maximal advantage of in case it works well.
Short and Long Range
If we focus our attention specifically on short-range forks - forks lasting less than some number of blocks, perhaps 3000, then there actually is a solution to the nothing at stake problem: security deposits. In order to be eligible to receive a reward for voting on a block, the user must put down a security deposit, and if the user is caught either voting on multiple forks then a proof of that transaction can be put into the original chain, taking the reward away. Hence, voting for only a single fork once again becomes the dominant strategy.

Another set of strategies, called "Slasher 2.0" (in contrast to Slasher 1.0, the original security deposit-based proof of stake algorithm), involves simply penalizing voters that vote on the wrong fork, not voters that double-vote. This makes analysis substantially simpler, as it removes the need to pre-select voters many blocks in advance to prevent probabilistic double-voting strategies, although it does have the cost that users may be unwilling to sign anything if there are two alternatives of a block at a given height. If we want to give users the option to sign in such circumstances, a variant of logarithmic scoring rules can be used (see here for more detailed investigation). For the purposes of this discussion, Slasher 1.0 and Slasher 2.0 have identical properties.

The reason why this only works for short-range forks is simple: the user has to have the right to withdraw the security deposit eventually, and once the deposit is withdrawn there is no longer any incentive not to vote on a long-range fork starting far back in time using those coins. One class of strategies that attempt to deal with this is making the deposit permanent, but these approaches have a problem of their own: unless the value of a coin constantly grows so as to continually admit new signers, the consensus set ends up ossifying into a sort of permanent nobility. Given that one of the main ideological grievances that has led to cryptocurrency's popularity is precisely the fact that centralization tends to ossify into nobilities that retain permanent power, copying such a property will likely be unacceptable to most users, at least for blockchains that are meant to be permanent. A nobility model may well be precisely the correct approach for special-purpose ephemeral blockchains that are meant to die quickly (eg. one might imagine such a blockchain existing for a round of a blockchain-based game).
One class of approaches at solving the problem is to combine the Slasher mechanism described above for short-range forks with a backup, transactions-as-proof-of-stake, for long range forks. TaPoS essentially works by counting transaction fees as part of a block's "score" (and requiring every transaction to include some bytes of a recent block hash to make transactions not trivially transferable), the theory being that a successful attack fork must spend a large quantity of fees catching up. However, this hybrid approach has a fundamental flaw: if we assume that the probability of an attack succeeding is near-zero, then every signer has an incentive to offer a service of re-signing all of their transactions onto a new blockchain in exchange for a small fee; hence, a zero probability of attacks succeeding is not game-theoretically stable. Does every user setting up their own node.js webapp to accept bribes sound unrealistic? Well, if so, there's a much easier way of doing it: sell old, no-longer-used, private keys on the black market. Even without black markets, a proof of stake system would forever be under the threat of the individuals that originally participated in the pre-sale and had a share of genesis block issuance eventually finding each other and coming together to launch a fork.
Because of all the arguments above, we can safely conclude that this threat of an attacker building up a fork from arbitrarily long range is unfortunately fundamental, and in all non-degenerate implementations the issue is fatal to a proof of stake algorithm's success in the proof of work security model. However, we can get around this fundamental barrier with a slight, but nevertheless fundamental, change in the security model.
Weak Subjectivity
Although there are many ways to categorize consensus algorithms, the division that we will focus on for the rest of this discussion is the following. First, we will provide the two most common paradigms today:
- Objective: a new node coming onto the network with no knowledge except (i) the protocol definition and (ii) the set of all blocks and other "important" messages that have been published can independently come to the exact same conclusion as the rest of the network on the current state.
- Subjective: the system has stable states where different nodes come to different conclusions, and a large amount of social information (ie. reputation) is required in order to participate.
Systems that use social networks as their consensus set (eg. Ripple) are all necessarily subjective; a new node that knows nothing but the protocol and the data can be convinced by an attacker that their 100000 nodes are trustworthy, and without reputation there is no way to deal with that attack. Proof of work, on the other hand, is objective: the current state is always the state that contains the highest expected amount of proof of work.
Now, for proof of stake, we will add a third paradigm:
- Weakly subjective: a new node coming onto the network with no knowledge except (i) the protocol definition, (ii) the set of all blocks and other "important" messages that have been published and (iii) a state from less than N blocks ago that is known to be valid can independently come to the exact same conclusion as the rest of the network on the current state, unless there is an attacker that permanently has more than X percent control over the consensus set.
Under this model, we can clearly see how proof of stake works perfectly fine: we simply forbid nodes from reverting more than N blocks, and set N to be the security deposit length. That is to say, if state S has been valid and has become an ancestor of at least N valid states, then from that point on no state S' which is not a descendant of S can be valid. Long-range attacks are no longer a problem, for the trivial reason that we have simply said that long-range forks are invalid as part of the protocol definition. This rule clearly is weakly subjective, with the added bonus that X = 100% (ie. no attack can cause permanent disruption unless it lasts more than N blocks).
Another weakly subjective scoring method is exponential subjective scoring, defined as follows:
- Every state S maintains a "score" and a "gravity"
- score(genesis) = 0, gravity(genesis) = 1
- score(block) = score(block.parent) + weight(block) * gravity(block.parent), where weight(block) is usually 1, though more advanced weight functions can also be used (eg. in Bitcoin, weight(block) = block.difficulty can work well)
- If a node sees a new block B' with B as parent, then if n is the length of the longest chain of descendants from B at that time, gravity(B') = gravity(B) * 0.99 ^ n (note that values other than 0.99 can also be used).

Essentially, we explicitly penalize forks that come later. ESS has the property that, unlike more naive approaches at subjectivity, it mostly avoids permanent network splits; if the time between the first node on the network hearing about block B and the last node on the network hearing about block B is an interval of k blocks, then a fork is unsustainable unless the lengths of the two forks remain forever within roughly k percent of each other (if that is the case, then the differing gravities of the forks will ensure that half of the network will forever see one fork as higher-scoring and the other half will support the other fork). Hence, ESS is weakly subjective with X roughly corresponding to how close to a 50/50 network split the attacker can create (eg. if the attacker can create a 70/30 split, then X = 0.29).
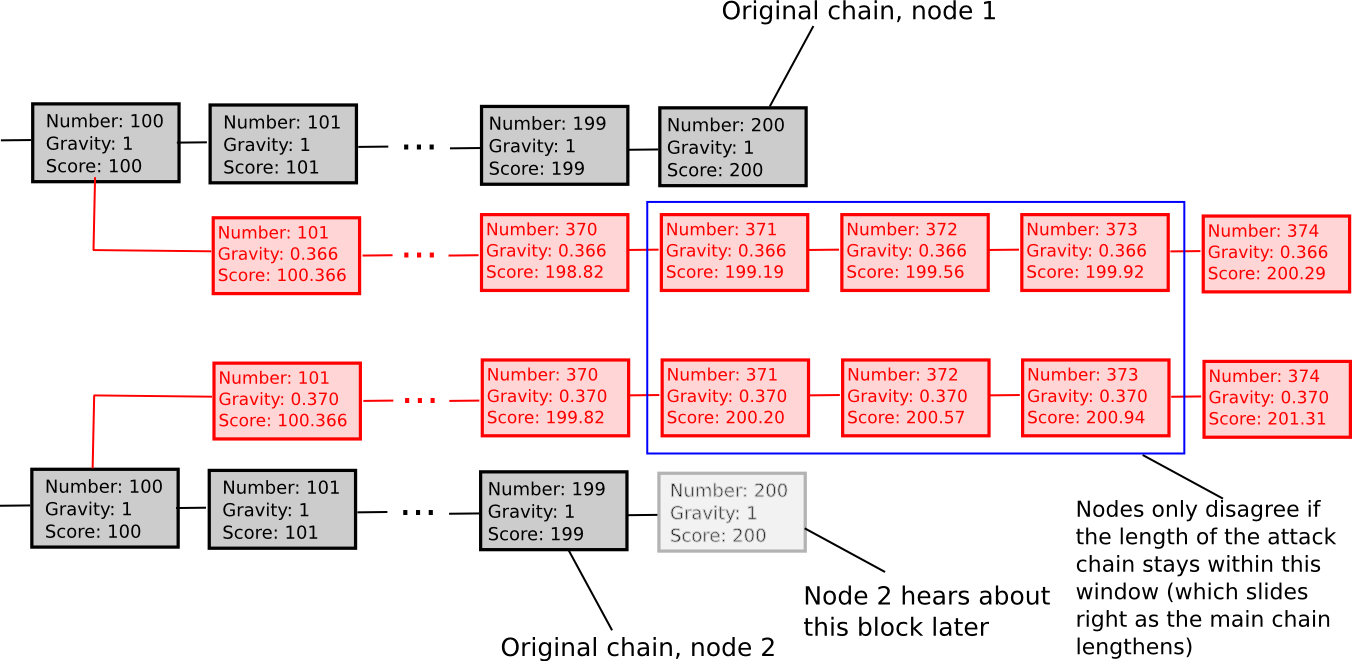
In general, the "max revert N blocks" rule is superior and less complex, but ESS may prove to make more sense in situations where users are fine with high degrees of subjectivity (ie. N being small) in exchange for a rapid ascent to very high degrees of security (ie. immune to a 99% attack after N blocks).
Consequences
So what would a world powered by weakly subjective consensus look like? First of all, nodes that are always online would be fine; in those cases weak subjectivity is by definition equivalent to objectivity. Nodes that pop online once in a while, or at least once every N blocks, would also be fine, because they would be able to constantly get an updated state of the network. However, new nodes joining the network, and nodes that appear online after a very long time, would not have the consensus algorithm reliably protecting them. Fortunately, for them, the solution is simple: the first time they sign up, and every time they stay offline for a very very long time, they need only get a recent block hash from a friend, a blockchain explorer, or simply their software provider, and paste it into their blockchain client as a "checkpoint". They will then be able to securely update their view of the current state from there.
This security assumption, the idea of "getting a block hash from a friend", may seem unrigorous to many; Bitcoin developers often make the point that if the solution to long-range attacks is some alternative deciding mechanism X, then the security of the blockchain ultimately depends on X, and so the algorithm is in reality no more secure than using X directly - implying that most X, including our social-consensus-driven approach, are insecure.
However, this logic ignores why consensus algorithms exist in the first place. Consensus is a social process, and human beings are fairly good at engaging in consensus on our own without any help from algorithms; perhaps the best example is the Rai stones, where a tribe in Yap essentially maintained a blockchain recording changes to the ownership of stones (used as a Bitcoin-like zero-intrinsic-value asset) as part of its collective memory. The reason why consensus algorithms are needed is, quite simply, because humans do not have infinite computational power, and prefer to rely on software agents to maintain consensus for us. Software agents are very smart, in the sense that they can maintain consensus on extremely large states with extremely complex rulesets with perfect precision, but they are also very ignorant, in the sense that they have very little social information, and the challenge of consensus algorithms is that of creating an algorithm that requires as little input of social information as possible.
Weak subjectivity is exactly the correct solution. It solves the long-range problems with proof of stake by relying on human-driven social information, but leaves to a consensus algorithm the role of increasing the speed of consensus from many weeks to twelve seconds and of allowing the use of highly complex rulesets and a large state. The role of human-driven consensus is relegated to maintaining consensus on block hashes over long periods of time, something which people are perfectly good at. A hypothetical oppressive government which is powerful enough to actually cause confusion over the true value of a block hash from one year ago would also be powerful enough to overpower any proof of work algorithm, or cause confusion about the rules of blockchain protocol.
Note that we do not need to fix N; theoretically, we can come up with an algorithm that allows users to keep their deposits locked down for longer than N blocks, and users can then take advantage of those deposits to get a much more fine-grained reading of their security level. For example, if a user has not logged in since T blocks ago, and 23% of deposits have term length greater than T, then the user can come up with their own subjective scoring function that ignores signatures with newer deposits, and thereby be secure against attacks with up to 11.5% of total stake. An increasing interest rate curve can be used to incentivize longer-term deposits over shorter ones, or for simplicity we can just rely on altruism-prime.
Marginal Cost: The Other Objection
One objection to long-term deposits is that it incentivizes users to keep their capital locked up, which is inefficient, the exact same problem as proof of work. However, there are four counterpoints to this.
First, marginal cost is not total cost, and the ratio of total cost divided by marginal cost is much less for proof of stake than proof of work. A user will likely experience close to no pain from locking up 50% of their capital for a few months, a slight amount of pain from locking up 70%, but would find locking up more than 85% intolerable without a large reward. Additionally, different users have very different preferences for how willing they are to lock up capital. Because of these two factors put together, regardless of what the equilibrium interest rate ends up being, the vast majority of the capital will be locked up at far below marginal cost.
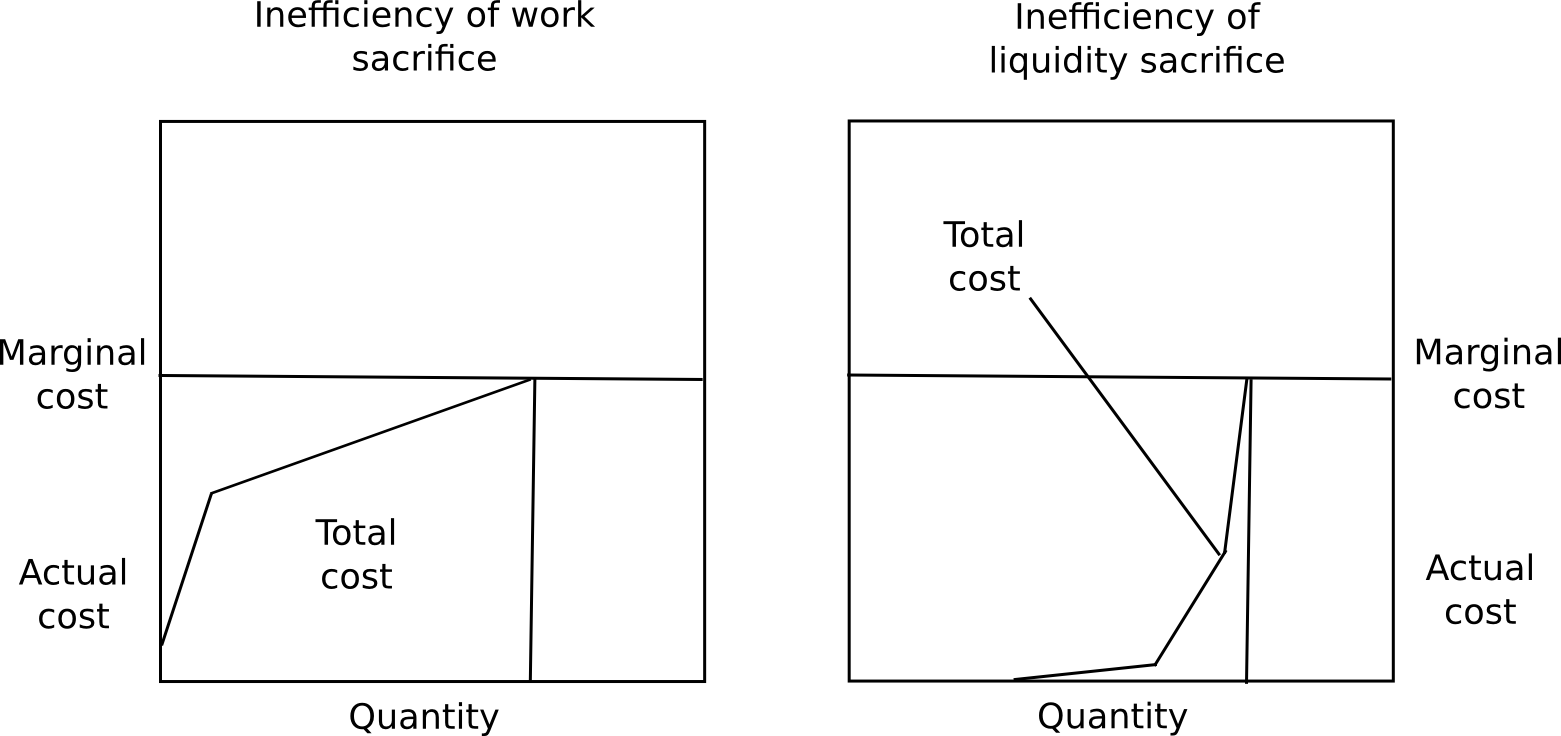
Second, locking up capital is a private cost, but also a public good. The presence of locked up capital means that there is less money supply available for transactional purposes, and so the value of the currency will increase, redistributing the capital to everyone else, creating a social benefit. Third, security deposits are a very safe store of value, so (i) they substitute the use of money as a personal crisis insurance tool, and (ii) many users will be able to take out loans in the same currency collateralized by the security deposit. Finally, because proof of stake can actually take away deposits for misbehaving, and not just rewards, it is capable of achieving a level of security much higher than the level of rewards, whereas in the case of proof of work the level of security can only equal the level of rewards. There is no way for a proof of work protocol to destroy misbehaving miners' ASICs.
Fortunately, there is a way to test those assumptions: launch a proof of stake coin with a stake reward of 1%, 2%, 3%, etc per year, and see just how large a percentage of coins become deposits in each case. Users will not act against their own interests, so we can simply use the quantity of funds spent on consensus as a proxy for how much inefficiency the consensus algorithm introduces; if proof of stake has a reasonable level of security at a much lower reward level than proof of work, then we know that proof of stake is a more efficient consensus mechanism, and we can use the levels of participation at different reward levels to get an accurate idea of the ratio between total cost and marginal cost. Ultimately, it may take years to get an exact idea of just how large the capital lockup costs are.
Altogether, we now know for certain that (i) proof of stake algorithms can be made secure, and weak subjectivity is both sufficient and necessary as a fundamental change in the security model to sidestep nothing-at-stake concerns to accomplish this goal, and (ii) there are substantial economic reasons to believe that proof of stake actually is much more economically efficient than proof of work. Proof of stake is not an unknown; the past six months of formalization and research have determined exactly where the strengths and weaknesses lie, at least to as large extent as with proof of work, where mining centralization uncertainties may well forever abound. Now, it's simply a matter of standardizing the algorithms, and giving blockchain developers the choice.