


The following are some interesting results on the performance of different miners over the course of the first 280,000 blocks of the Ethereum blockchain. For this timespan I have collected the list of block and uncle coinbase addresses; raw data can be found here for blocks and here for uncles, and from this we can glean a lot of interesting information particularly about stale rates and how well-connected the different miners and pools are.
First off, the scatter plot:
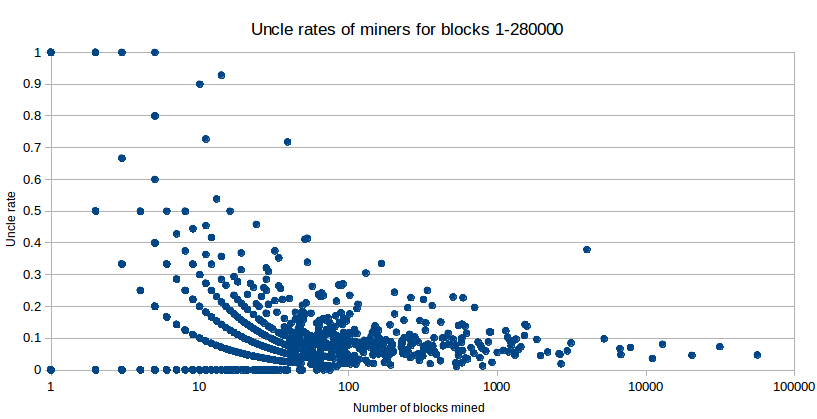
What we clearly see here are a few primary trends. First of all, uncle rates are quite low compared to Olympic; altogether we have seen 20750 uncles with 280000 blocks, or an uncle rate of 7.41% (if you compute this inclusively, ie. uncles as a percentage of all blocks rather than uncles per block, you get 6.89%) - in short, not that much higher than similar figures for bitcoin even back in 2011, when its mining ecosystem was more similar to Ethereum's with CPU and GPUs still being dominant and with a low transaction volume. Note that this does not mean that miners are getting only 93.11% of the revenue that they would be if they were infinitely well-connected to everyone else; Ethereum's uncle mechanic effectively cuts out ~87% of the difference, so the actual "average loss" from bad connectivity is only ~0.9%. That said, these losses will increase for two reasons once the network starts seeing more transactions: first, the uncle mechanic works with base block rewards only, not transaction fees, and second, larger blocks necessarily lead to longer propagation times.
Second, we can see that there is a general trend that larger miners have lower uncle rates. This is, of course, to be expected, though it is important to dissect (1) why this happens, and (2) to what extent this is actually a real effect and not simply a statistical artefact of the fact that smaller samples tend to have more extreme results.
Segregating by miner size, the statistics are as follows:
| Number of blocks mined | Average uncle rate |
| <= 10 | 0.127 |
| 10-100 | 0.097 |
| 100-1000 | 0.087 |
| 1000-10000 | 0.089* |
| >= 10000 | 0.055 |
There are four primary hypotheses that can explain these results:
- Professionalism disparity: large miners are professional operations and have more resources available to invest in improving their overall connectivity to the network (eg. by purchasing better wireless, by watching more carefully to see if their uncle rates are highly suboptimal due to networking issues), and thus have higher efficiency. Small miners on the other hand tend to be hobbyists on their laptops, and may not be particularly well-connected to the internet.
- Last-block effect: the miner that produced the last block "finds out" about the block immediately rather than after waiting ~1 second for it to propagate through the network, and thus gains an advantage in finding the next block
- Pool efficiency: the very large miners are pools, and pools are for some reason likely related to networking more efficient than solo miners.
- Time period differences: pools and other very large miners were not active on the first day of the blockchain, when block times were very fast and uncle rates were very high.
The fact that professionalism disparity seems to dominate is in some sense an encouraging sign, especially since (i) the factor matters more at small to medium scales than it does at medium to large scales, and (ii) individual miners tend to have countervailing economic factors that outweigh their reduced efficiency - particularly, the fact that they are using hardware that they largely already paid for.
Now, what about the jump from 7.1% at 1000-10000 blocks to 5.5% for everyone above that? The last-block effect can account for about 40% of the effect, but not all of it (quick math: the average miner in the former cohort has a network share of 1%, in the latter cohort 10%, and the difference of 9% should project a decrease from 7.1* to 7.1% * 0.93 = 6.4%), though given the small number of miners it's important to note that any finding here should be taken as being highly tentative at best.
The key characteristic of the miners above 10000 blocks, quite naturally, is that they are pools (or at least three of the five; the other two are solo miners though they are the smallest ones). Interestingly enough, the two non-pools have uncle rates of 8.1% and 3.5% respectively, a weighted average of 6.0% which is not much different from the 5.4% weighted average stale rate of the three pools; hence, in general, it seems as though the pools are very slightly more efficient than the solo miners, but once again the finding should not be taken as statistically significant; even though the sample size within each pool is very large, the sample size of pools is small. What's more, the more efficient mining pool is not actually the largest one (nanopool) - it's suprnova.
This leads us to an interesting question: where do the efficiencies and inefficiencies of pooled mining come from? On one hand, pools are likely very well connected to the network and do a good job of spreading their own blocks; they also benefit from a weaker version of the last-block effect (weaker version because there is still the single-hop round trip from miner to pool to miner). On the other hand, the delay in getting work from a pool after creating a block should slightly increase one's stale rate: assuming a network latency of 200ms, by about 1%. It's likely that these forces roughly cancel out.
The third key thing to measure is: just how much of the disparities that we see is because of a genuine inequality in how well-connected miners are, and how much is random chance? To check this, we can do a simple statistical test. Here are the deciles of the uncle rates of all miners that produced more than 100 blocks (ie. the first number is the lowest uncle rate, the second number is the 10th percentile, the third is the 20th percentile and so on until the last number is the highest):
[0.01125703564727955, 0.03481012658227848, 0.04812518452908179, 0.0582010582010582, 0.06701030927835051, 0.07642487046632124, 0.0847457627118644, 0.09588299024918744, 0.11538461538461539, 0.14803625377643503, 0.3787765293383271]
Here are the deciles generated by a random model where every miner has a 7.41% "natural" stale rate and all disparities are due to some being lucky or unlucky:
[0.03, 0.052980132450331126, 0.06140350877192982, 0.06594885598923284, 0.06948640483383686, 0.07207207207207207, 0.07488986784140969, 0.078125, 0.08302752293577982, 0.09230769230769231, 0.12857142857142856]
So we get roughly half of the effect. The other half actually does come from genuine connectivity differences; particularly, if you do a simple model where "natural" stale rates are random variables with a normal distribution around a mean of 0.09, standard deviation 0.06 and hard minimum 0 you get:
[0, 0.025374105400130124, 0.05084745762711865, 0.06557377049180328, 0.07669616519174041, 0.09032875837855091, 0.10062893081761007, 0.11311861743912019, 0.13307984790874525, 0.16252390057361377, 0.21085858585858586]
This is pretty close, although is does grow too fast on the low side and slowly on the high side; in reality, it seems that the best-fit "natural stale rate distribution" exhibits positive skewness, which we would expect given the dimishing returns in spending increasing effort on making oneself more and more well-connected to the network. All in all, the effects are not very large; especially when divided by 8 after the uncle mechanism is taken into account, the disparities are much smaller than the disparities in electricity costs. Hence, the best approaches to improving decentralization moving forward are arguably highly concentrated in coming up with more decentralized alternatives to mining pools; perhaps mining pools implementing something like Meni Rosenfeld's Multi-PPS may be a medium term solution.