


Oh wow, it's been a while... over 1.5 years since we've released Geth v1.9.0. We did do 26 point releases in that time frame (about one per three weeks), but pushing out a major release is always a bit more special. The adrenaline rush of shipping new features, coupled with the fear of something going horribly wrong. Still unsure if I like it or hate it. Either way, Ethereum is evolving and we need to push the envelope to keep up with it.
Without further ado, please welcome Geth v1.10.0 to the Ethereum family.
Here be dragons
Before diving into the details of our newest release, it's essential to emphasize that with any new feature, come new risks. To cater for users and projects with differing risk profiles, many of our heavy hitter features can be (for now) toggled on and off individually. Whether you read the entire content of this blog post - or only skim parts interesting to you - please read the 'Compatibility' section at the end of this document!
With that out of the way, let's dive in and see what Geth v1.10.0 is all about!
Berlin hard-fork
Let's get the elephant out of the room first. Geth v1.10.0 does not ship the Berlin hard-fork yet, as there was some 11th hour concerns from the Solidity team about EIP-2315. Since v1.10.0 is a major release, we don't want to publish it too close to the fork. We will follow up with v1.10.1 soon with the final list of EIPs and block numbers baked in.
Snapshots
We've been talking about snapshots for such a long time now, it feels strange to finally see them in a release. Without going into too many details (see linked post), snapshots are an acceleration data structure on top of the Ethereum state, that allows reading accounts and contract storage significantly faster.
To put a number on it, the snapshot feature reduces the cost of accessing an account from O(logN) to O(1). This might not seem like much at a first glance, but translated to practical terms, on mainnet with 140 million accounts, snapshots can save about 8 database lookups per account read. That's almost an order of magnitude less disk lookups, guaranteed constant independent of state size.
Whoa, does this mean we can 10x the gas limit? No, unfortunately. Whilst snapshots do grant us a 10x read performance, EVM execution also writes data, and these writes need to be Merkle proven. The Merkle proof requirement retains the necessity for O(logN) disk access on writes.
So, what's the point then?! Whilst fast read access to accounts and contract storage isn't enough to bump the gas limit, it does solve a few particularly thorny issues:
- DoS. In 2016, Ethereum sustained its worse DoS attack ever - The Shanghai Attacks - that lasted about 2-3 months. The attack revolved around bloating Ethereum's state and abusing various underpriced opcodes to grind the network to a halt. After numerous client optimizations and repricing hard forks, the attack was repelled. The root cause still lingers: state access opcodes have a fixed EVM gas cost O(1), but an ever slowly increasing execution cost O(logN). We've bumped the gas costs in Tangerine Whistle, Istanbul and now Berlin to bring the EVM costs back in line with the runtime costs, but these are stopgap measures. Snapshots on the other hand reduce execution cost of state reads to O(1) - in line with EVM costs - thus solves the read-based DoS issues long term (don't quote me on that).
- Call. Checking a smart contract's state in Ethereum entails a mini EVM execution. Part of that is running bytecode and part of it is reading state slots from disk. If you have your personal Ethereum node that you only use for your own personal needs, there's a high chance that the current state access speed is more than adequate. If you're operating a node for the consumption of multiple users however, the 10x performance improvement granted by snapshots means that you can serve 10x as many queries at +- the same cost to you.
- Sync. There are two major ways you can synchronize an Ethereum node. You can download the blocks and execute all the transactions within; or you can download the blocks, verify the PoWs and download the state associated a recent block. The latter is much faster, but it relies on benefactors serving you a copy of the recent state. With the current Merkle-Patricia state model, these benefactors read 16TB of data off disk to serve a syncing node. Snapshots enable serving nodes to read only 96GB of data off disk to get a new node joined into the network. More on this in the Snap sync section.
As with all features, it's a game of tradeoffs. Whilst snapshots have enormous benefits, that we believe in strongly enough to enable for everyone, there are certain costs to them:
- A snapshot is a redundant copy of the raw Ethereum state already contained in the leaves of the Merkle Patricia trie. As such, snapshots entail an additional disk overhead of about 20-25GB on mainnet currently. Hopefully snapshots will allow us to do some further state optimizations and potentially remove some of the disk overhead of Merkle tries as they are currently.
- Since nobody has snapshots constructed in the network yet, nodes will initially need to bear the cost of iterating the state trie and creating the initial snapshot themselves. Depending on the load to your node, this might take anywhere between a day to a week, but you only need to do it once in the lifetime of your node (if things work as intended). The snapshot generation runs in the background, concurrently with all other node operations. We have plans to not require this once snapshots are generally available in the network. More on this in the Snap sync section.
If you are not confident about the snapshot feature, you can disable it in Geth 1.10.0 via --snapshot=false, but be advised that we will make it mandatory long term to guarantee a baseline network health.
Snap sync
If you thought snapshots took a long time to ship, wait till you hear about snap sync! We've implemented the initial prototype of a new synchronization algorithm way back in October, 2017... then sat on the idea for over 3 years?! 🤯 Before diving in, a bit of history.
When Ethereum launched, you could choose from two different ways to synchronize the network: full sync and fast sync (omitting light clients from this discussion). Full sync operated by downloading the entire chain and executing all transactions; vs. fast sync placed an initial trust in a recent-ish block, and directly downloaded the state associated with it (after which it switched to block execution like full sync). Although both modes of operation resulted in the same final dataset, they preferred different tradeoffs:
- Full sync minimized trust, choosing to execute all transactions from genesis to head. Whilst it might be the most secure option, Ethereum mainnet currently contains over 1.03 billion transactions, growing at a rate of 1.25 million / day. Chosing to execute everything from genesis means full sync has a forever increasing cost. Currently it takes 8-10 days to process all those transactions on a fairly powerful machine.
- Fast sync chose to rely on the security of the PoWs. Instead of executing all transactions, it assumed that a block with 64 valid PoWs on top would be prohibitively expensive for someone to construct, as such it's ok to download the state associated with HEAD-64. Fast sync trusting the state root from a recent block, it could download the state trie directly. This replaced the need of CPU & disk IO with a need for network bandwidth and latency. Specifically, Ethereum mainnet currently contains about 675 million state trie nodes, taking about 8-10 hours to download on a fairly well connected machine.
Full sync remained available for anyone who wanted to expend the resources to verify Ethereum's entire history, but for most people, fast sync was more than adequate™. There's a computer science paradox, that once a system reaches 50x the usage it was designed at, it will break down. The logic is, that irrelevant how something works, push it hard enough and an unforeseen bottleneck will appear.
In the case of fast sync, the unforeseen bottleneck was latency, caused by Ethereum's data model. Ethereum's state trie is a Merkle tree, where the leaves contain the useful data and each node above is the hash of 16 children. Syncing from the root of the tree (the hash embedded in a block header), the only way to download everything is to request each node one-by-one. With 675 million nodes to download, even by batching 384 requests together, it ends up needing 1.75 million round-trips. Assuming an overly generous 50ms RTT to 10 serving peers, fast sync is essentially waiting for over 150 minutes for data to arrive. But network latency is only 1/3rd of the problem.
When a serving peer receives a request for trie nodes, it needs to retrieve them from disk. Ethereum's Merkle trie doesn't help here either. Since trie nodes are keyed by hash, there's no meaningful way to store/retrieve them batched, each requiring it's own database read. To make matters worse, LevelDB (used by Geth) stores data in 7 levels, so a random read will generally touch as many files. Multiplying it all up, a single network request of 384 nodes - at 7 reads a pop - amounts to 2.7 thousand disk reads. With the fastest SATA SSDs' speed of 100.000 IOPS, that's 37ms extra latency. With the same 10 serving peer assumption as above, fast sync just added an extra 108 minutes waiting time. But serving latency is only 1/3 of the problem.
Requesting that many trie nodes individually means actually uploading that many hashes to remote peers to serve. With 675 million nodes to download, that's 675 million hashes to upload, or 675 * 32 bytes = 21GB. At a global average of 51Mbps upload speed (X Doubt), fast sync just added an extra 56 minutes waiting time. Downloads are a bit more than twice as large, so with global averages of 97Mbps, *fast sync* popped on a further 63 minutes. Bandwidth delays are the last 1/3 of the problem.
Sum it all up, and fast sync spends a whopping 6.3 hours doing nothing, just waiting for data:
- If you have an above average network link
- If you have a good number of serving peers
- If your peers don't serve anyone else but you
Snap sync was designed to solve all three of the enumerated problems. The core idea is fairly simple: instead of downloading the trie node-by-node, snap sync downloads the contiguous chunks of useful state data, and reconstructs the Merkle trie locally:
- Without downloading intermediate Merkle trie nodes, state data can be fetched in large batches, removing the delay caused by network latency.
- Without downloading Merkle nodes, downstream data drops to half; and without addressing each piece of data individually, upstream data gets insignificant, removing the delay caused by bandwidth.
- Without requesting randomly keyed data, peers do only a couple contiguous disk reads to serve the responses, removing the delay of disk IO (iff the peers already have the data stored in an appropriate flat format).
Whilst snap sync is eerily similar to Parity's warp sync - and indeed took many design ideas from it - there are significant improvements over the latter:
- Warp sync relies on static snapshots created every 30000 blocks. This means serving nodes need to regenerate the snapshots every 5 days or so, but iterating the entire state trie can actually take more time than that. This means warp sync is not sustainable long term. Opposed to this, snap sync is based on dynamic snapshots, which are generated only once, no matter how slowly, and then are kept up to date as the chain progresses.
- Warp sync's snapshot format does not follow the Merkle trie layout, and as such chunks of warp-data cannot be individually proven. Syncing nodes need to download the entire 20+GB dataset before they can verify it. This means warp syncing nodes could be theoretically grieved. Opposed to this, snap sync's snapshot format is just the sequential Merkle leaves, which allows any range to be proven, thus bad data is detected immediately.
To put a number on snap sync vs fast sync, synchronizing the mainnet state (ignoring blocks and receipts, as those are the same) against 3 serving peers, at block ~#11,177,000 produced the following results:
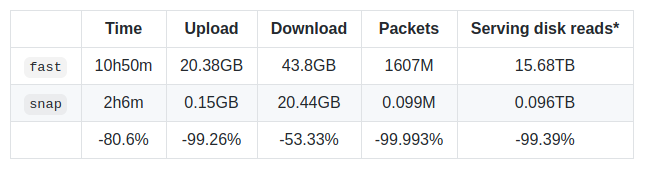
Do note, that snap sync is shipped, but not yet enabled, in Geth v1.10.0. The reason is that serving snap sync requires nodes to have the snapshot acceleration structure already generated, which nobody has yet, as it is also shipped in v1.10.0. You can manually enable snap sync via --syncmode snap, but be advised that we expect it not to find suitable peers until a few weeks after Berlin. We'll enable it by default when we feel there are enough peers to rely on it.
Offline pruning
We're really proud of what we've achieved with Geth over the past years. Yet, there's always that one topic, which makes you flinch when asked about. For Geth, that topic is state pruning. But what is pruning and why is it needed?
When processing a new block, a node takes the current state of the network as input data and mutates it according to the transactions in the block, generating a new, output data. The output state is mostly the same as the input, only a few thousand items modified. Since we can't just overwrite the old state (otherwise we couldn't handle block reorgs), both old and new end up on disk. (Ok, we're a bit smarter and only push new diffs to disk if they stick around and don't get deleted in the next few blocks, but let's ignore that part for now).
Pushing these new pieces of state data, block-by-block, to the database is a problem. They keep accumulating. In theory we could "just delete" state data that's old enough to not run the risk of a reorg, but as it turns out, that's quite a hard problem. Since state in Ethereum is stored in a tree data structure - and since most blocks only change a small fraction of the state - these trees share huge portions of the data with one another. We can easily decide if the root of an old trie is stale and can be deleted, but it's exceedingly costly to figure out if a node deep within an old state is still referenced by anything newer or not.
Throughout the years, we've implemented a range of pruning algorithms to delete leftovers (lost count, around 10), yet we've never found a solution that doesn't break down if enough data is thrown at it. As such, people grew accustomed that Geth's database starts slim after a fast sync, and keeps growing until you get fed up and resync. This is frustrating to say the least, as re-downloading everything just wastes bandwidth and adds meaningless downtime to the node.
Geth v1.10.0 doesn't quite solve the problem, but it takes a big step towards a better user experience. If you have snapshots enabled and fully generated, Geth can use those as an acceleration structure to relatively quickly determine which trie nodes should be kept and which should be deleted. Pruning trie nodes based on snapshots does have the drawback that the chain may not progress during pruning. This means, that you need to stop Geth, prune its database and then restart it.
Execution time wise, pruning takes a few hours (greatly depends on your disk speed and accumulated junk), one third of which is indexing recent trie node from snapshots, one third deleting stale trie nodes and the last third compacting the database to reclaim freed up space. At the end of the process, your disk usage should approximately be the same as if you did a fresh sync. To prune your database, please run geth snapshot prune-state.
Be advised, that pruning is a new and dangerous feature, a failure of which can cause bad blocks. We're confident that it's reliable, but if something goes wrong, there's likely no way to salvage the database. Our recommendation - at least until the feature gets battle tested - is to back up your database prior to pruning, and try with testnet nodes first before going all in on mainnet.
Transaction unindexing
Ethereum has been around for a while now, and in its almost 6 years' of existence, Ethereum's users issued over 1 billion transactions. That's a big number.
Node operators always took it for granted that they can look up an arbitrary transaction from the past, given only its hash. Truth be told, it seems like a no-brainer thing to do. Running the numbers though, we end up in a surprising place. To make transactions searchable, we need to - at minimum - map the entire range of transaction hashes to the blocks they are in. With all tradeoffs made towards minimizing storage, we still need to store 1 block number (4 bytes) associated with 1 hash (32 bytes).
36 bytes / transaction doesn't seem much, but multiplying with 1 billion transactions ends up at an impressive 36GB of storage, needed to be able to say transaction 0xdeadbeef is in block N. It's a lot of data and a lot of database entries to shuffle around. Storing 36GB is an acceptable price if you want to look up transactions 6 years back, but in practice, most users don't want to. For them, the extra disk usage and IO overhead is wasted resources. It's also important to note that transaction indices are not part of consensus and are not part of the network protocol. They are purely a locally generated acceleration structure.
Can we shave some - for us - useless data off of our nodes? Yes! Geth v1.10.0 switches on transaction unindexing by default and sets it to 2,350,000 blocks (about 1 year). The transaction unindexer will linger in the background, and every time a new block arrives, it ensures that only transactions from the most recent N blocks are indexed, deleting older ones. If a user decides they want access to older transactions, they can restart Geth with a higher --txlookuplimit value, and any blocks missing from the updated range will be reindexed (note, the trigger is still block import, you have to wait for 1 new block).
Since about 1/3rd of Ethereum's transaction load happened in 2020, keeping an entire year's worth of transaction index will still have a noticeable weight on the database. The goal of transaction unindexing is not to remove an existing feature in the name of saving space. The goal is to move towards a mode of operation where space does not grow indefinitely with chain history.
If you wish to disable transaction unindexing altogether, you can run Geth with --txlookuplimit=0, which reverts to the old behavior of retaining the lookup map for every transaction since genesis.
Preimage discarding
Ethereum stores all its data in a Merkle Patricia trie. The values in the leaves are the raw data being stored (e.g. storage slot content, account content), and the path to the leaf is the key at which the data is stored. The keys however are not the account addresses or storage addresses, rather the Keccak256 hashes of those. This helps balance the branch depths of the state tries. Using hashes for keys is fine as users of Ethereum only ever reference the original addresses, which can be hashed on the fly.
There is one use case, however, where someone has a hash stored in the state trie and wants to recover it's preimage: debugging. When stepping over an EVM bytecode, a developer might want to glipmse over all the variables in the smart contract. The data is there, but without the preimages, its hard to say which data corresponds to which Solidity variable.
Originally Geth had a half-baked solution. We stored in the database all preimages that originated from user calls (e.g. sending a transaction), but not those originating from EVM calls (e.g. accessing a slot). This was not enough for Remix, so we extended our tracing API calls to support saving the preimages for all SHA3 (Keccak256) operations. Although this solved the debugging issue for Remix, it raised the question about all that data unused by non-debugging nodes.
The preimages aren't particularly heavy. If you do a full sync from genesis - reexecuting all the transactions - you'll only end up with 5GB extra load. Still, there is no reason to keep that data around for users not using it, as it only increases the load on LevelDB compactions. As such, Geth v1.10.0 disables preimage collection by default, but there's no mechanism to actively delete already stored preimages.
If you are using your Geth instance to debug transactions, you can retain the original behavior via --cache.preimages. Please note, it is not possible to regenerate preimages after the fact. If you run Geth with preimage collection disabled and change your mind, you'll need to reimport the blocks.
ETH/66 protocol
The eth/66 protocol is a fairly small change, yet has quite a number of beneficial implications. In short, the protocol introduces request and reply IDs for all bidirectional packets. The goal behind these IDs is to more easily match up responses to requests, specifically, to more easily deliver a response to a subsystem that made the original request.
These IDs are not essential, and indeed we've been happily working around the lack of them these past 6 years. Unfortunately, all code that needs to request anything from the network becomes overly complicated, if multiple subsystems can request the same type of data concurrently. E.g. block headers can be requested by the downloader syncing the chain; it can be requested by the fetcher fulfilling block announcements; and it can be requested by fork challenges. Furthermore, timeouts can cause late/unexpected deliveries or re-requests. In all these cases, when a header packet arrives, every subsystem peeks at the data and tries to figure out if it was meant for itself or someone else. Consuming a reply not meant for a particular subsystem will cause a failure elsewhere, which needs graceful handling. It just gets messy. Doable, but messy.
The importance of eth/66 in the scope of this blog post is not that it solves a particular problem, rather that it is introduced prior to the Berlin hard-fork. As all nodes are expected to upgrade by the fork time, this means Geth can start deprecating the old protocols after the fork. Only after discontinuing all older protocols can we rewrite Geth's internals to take advantage of request ids. Following our protocol deprecation schedule, we'll be dropping eth/64 shortly and eth65 by the end of summer.
Some people might consider Geth using its weight to force protocol updates on other clients. We'd like to emphasize that the typed transactions feature from the Berlin hard-fork originally called for a new protocol version. As only Geth implemented the full suite of eth/xy protocols, other clients requested "hacking" it into old protocol versions to avoid having to focus on networking at this time. The agreement was that Geth backports typed transaction support into all its old protocol code to buy other devs time, but in exchange will phase out the old versions in 6 months to avoid stagnation.
ChainID enforcement
Way back in 2016, when TheDAO hard-fork passed, Ethereum introduced the notion of the chain id. The goal was to modify the digital signatures on transactions with a unique identifier to differentiate between what's valid on Ethereum and what's valid on Ethereum Classic (and what's valid on testnets). Making a transaction valid on one network but invalid on another ensures they cannot be replayed without the owner's knowledge.
In order to minimize issues around the transition, both new/protected and old/unprotected transactions remained valid. Fast forward 5 years, and about 15% of transaction on Ethereum are still not replay-protected. This doesn't mean there's an inherent vulnerability, unless you reuse the same keys across multiple networks. Top tip: Don't! Still, accidents happen, and certain Ethereum based networks have been known to go offline due to replay issues.
As much as we don't want to play big brother, we've decided to try and nudge people and tooling to abandon the old, unprotected signatures and use chain ids everywhere. The easy way would be to just make unprotected transactions invalid at the consensus level, but that would leave 15% of people stranded and scattering for hotfixes. To gradually move people towards safer alternatives without pulling the rug from underneath their feet, Geth v1.10.0 will reject transactions on the RPC that are not replay protected. Propagation through the P2P protocols remains unchanged for now, but we will be pushing for rejection there too long term.
If you are using code generated by abigen, we've included in the go-ethereum libraries additional signer constructors to allow easily creating chain-id-bound transactors. The legacy signers included out of the box were written before EIP155 and until now you needed to construct the protected signer yourself. As this was error prone and some people assumed we guessed the chain ID internally, we decided to introduce direct APIs ourselves. We will deprecate and remove the legacy signers in the long term.
Since we realize people/tooling issuing unprotected transactions can't change overnight, Geth v1.10.0 supports reverting to the old behavior and accepting non-EIP155 transactions via --rpc.allow-unprotected-txs. Be advised that this is a temporary mechanism that will be removed long term.
Database introspection
Every now and again we receive an issue report about a corrupted database, with no real way to debug it. Shipping a 300GB data directory to us is not feasible, and sending custom dissection tools to users is cumbersome. Also since a corrupted database often manifests itself in an inability to start up Geth, even using debugging RPC APIs are useless.
Geth v1.10.0 ships a built-in database introspection tool to try and alleviate the situation a bit. It is a very low level accessor to LevelDB, but it allows arbitrary data retrievals, insertions and deletions. We are unsure how useful these will turn out to be, but they at least give a fighting chance to restore a broken node without having to resync.
The supported commands are:
- geth db inspect - Inspect the storage size for each type of data in the database
- geth db stats - Print various database usage and compaction statistics
- geth db compact - Compact the database, optimizing read access (super slow)
- geth db get - Retrieve and print the value of a database key
- geth db delete - Delete a database key (super dangerous)
- geth db put - Set the value of a database key (super dangerous)
Flag deprecations
Throughout the v1.9.x release family we've marked a number of CLI flags deprecated. Some of them were renamed to better follow our naming conventions, others were removed due to dropped features (notably Whisper). Throughout the previous release family, we've kept the old deprecated flags functional too, only printing a warning when used instead of the recommended versions.
Geth v1.10.0 takes the opportunity to completely remove support for the old CLI flags. Below is a list to help you fix your commands if you by any chance haven't yet upgraded to the new versions the past year:
- --rpc -> --http - Enable the HTTP-RPC server
- --rpcaddr -> --http.addr - HTTP-RPC server listening interface
- --rpcport -> --http.port - HTTP-RPC server listening port
- --rpccorsdomain -> --http.corsdomain - Domain from which to accept requests
- --rpcvhosts -> --http.vhosts - Virtual hostnames from which to accept requests
- --rpcapi -> --http.api - API's offered over the HTTP-RPC interface
- --wsaddr -> --ws.addr - WS-RPC server listening interface
- --wsport -> --ws.port - WS-RPC server listening port
- --wsorigins -> --ws.origins - Origins from which to accept websockets requests
- --wsapi -> --ws.api - API's offered over the WS-RPC interface
- --gpoblocks -> --gpo.blocks - Number of blocks to check for gas prices
- --gpopercentile -> --gpo.percentile - Percentile of recent txs to use as gas suggestion
- --graphql.addr -> --graphql - Enable GraphQL on the HTTP-RPC server
- --graphql.port -> --graphql - Enable GraphQL on the HTTP-RPC server
- --pprofport -> --pprof.port - Profiler HTTP server listening port
- --pprofaddr -> --pprof.addr - Profiler HTTP server listening interface
- --memprofilerate -> --pprof.memprofilerate - Turn on memory profiling with the given rate
- --blockprofilerate -> --pprof.blockprofilerate - Turn on block profiling with the given rate
- --cpuprofile -> --pprof.cpuprofile - Write CPU profile to the given file
A handful of the above listed legacy flags may still work for a few releases, but you should not rely on them remaining available.
Since most people running full nodes do not use USB wallets through Geth - and since USB handling is a bit quirky on different platforms - a lot of node operators just had to explicitly turn off USB via --nosub. To cater the defaults to the requirements of the many, Geth v1.10.0 disabled USB wallet support by default and deprecated the --nousb flag. You can still use USB wallets, just need to explicitly request it from now on via --usb.
Unclean shutdown tracking
Fairly often we receive bug reports that Geth started importing old blocks on startup. This phenomenon is generally caused by the node operator terminating Geth abruptly (power outage, OOM killer, too short shutdown timeout). Since Geth keeps a lot of dirty state in memory - to avoid writing to disk things that get stale a few blocks later - an abrupt shutdown can cause these to not be flushed. With recent state missing on startup, Geth has no choice but to rewind it's local chain to the point where it last saved the progress.
To avoid debating whether an operator did or did not shut down their node cleanly, and to avoid having a clean cycle after a crash hide the fact that data was lost, Geth v1.10.0 will start tracking and reporting node crashes. We're hopeful that this will allow operatos to detect that their infra is misconfigured or has issue before those turn into irreversible data loss.
WARN [03-03|06:36:38.734] Unclean shutdown detected booted=2021-02-03T06:47:28+0000 age=3w6d23h
Compatibility
Doing a major release so close to a hard fork is less than desired, to say the least. Unfortunately, shipping all the large features for the next generation Geth took 2 months longer than we've anticipated. To try and mitigate production problems that might occur from the upgrade, almost all new features can be toggled off via CLI flags. There is still 6 weeks left until the currently planned mainnet block, to ensure you have a smooth experience. Nonetheless, we apologize for any inconveniences in advance.
To revert as much functionality as possible to the v1.9.x feature-set, please run Geth with:
- --snapshot=false to disable the snapshot acceleration structure and snap sync
- --txlookuplimit=0 to keep indexing all transactions, not just the last year
- --cache.preimages tp keep generating and persisting account preimages
- --rpc.allow-unprotected-txs - to allow non-replay-protected signatures
- --usb - to reenable the USB wallet support
Note, the eth_protocolVersion API call is gone as it made no sense. If you have a very good reason as to why it's needed, please reach out to discuss it.
Epilogue
As with previous major releases, we’re really proud of this one too. We've delayed it quite a lot, but we did it in the name of stability to ensure that all the sensitive features are tested as well as we could. We're hopeful this new release family will open the doors to a bit more transaction throughput and a bit lower fees.
As with all our previous releases, you can find the:
- Source code, git tags and whatnot on our GitHub release page.
- Pre-built binaries for all platforms on our downloads page.
- Docker images published under ethereum/client-go.
- Ubuntu packages in our Launchpad PPA repository.
- OSX packages in our Homebrew Tap repository.