


Although truly solving blockchain scalability fundamentally, that is to say figuring out a solution to the problem that every node must process every transaction, is a very hard problem, and all suggested solutions rely on either highly advanced cryptography or intricate multi-blockchain architectures, partial solutions that provide a constant-factor improvement over the way Bitcoin does things are actually quite easy to find. In Ethereum, for example, we have the concept of a separate state tree and transaction history, allowing miners to easily store only existing account states and not historical transaction outputs that are no longer relevant and thereby drastically reducing the amount of storage that would be required; if Bitcoin is any indication, savings should be around 90%. Another improvement is the use of accounts instead of coins/UTXO as the fundamental unit, allowing each user to take up less than a hundred bytes on the blockchain regardless of how many transactions go in and out of their account. Of course, both of these are partially, or perhaps even fully, offset by the fact that Ethereum has a much larger scope, intending to use the blockchain for much more than just monetary transactions, but even if that is true it makes scalability all the more necessary. What I am about to describe in this article is another anti-bloat strategy that could potentially be used to achieve very substantial gains, this time targeting the issue of “dust”.
Dust, in simple terms, refers to the accumulation of tiny outputs (or accounts) on the blockchain, perhaps with only a fraction of a cent worth of coin, that are either dumped onto the blockchain maliciously or are simply too low-value to be even worth the increased transaction fee to send. On Ethereum, dust of the second kind can also consist of accounts that have zero balance left, perhaps because the user might want to switch to a different private key for security reasons. Dust is a serious problem; it is estimated that the majority of the Bitcoin blockchain is dust, and in the case of Litecoin something like 90% of the outputs are the result of a single malicious blockchain spam attack that took place back to 2011. In Ethereum, there is a storage fee onSSTORE in order to charge for adding something to the state, and the floating block limit system ensures that even a malicious miner has no significant advantage in this regard, but there is no concept of a fee charged over time; hence, there is no protection or incentive against a Litecoin-style attack affecting the Ethereum blockchain as well. But what if there was one? What if the blockchain could charge rent?
The basic idea behind charging rent is simple. Each account would keep track of how much space it takes up, including the [ nonce, balance, code, state_root ] header RLP and the storage tree, and then every block the balance would go down by RENTFEE multiplied by the amount of space taken up (which can be measured in bytes, for simplicity normalizing the total memory load of each storage slot to 64 bytes). If the balance of an account drops below zero, it would disappear from the blockchain. The hard part is implementation. Actually implementing this scheme is in one way easier and in one way harder than expected. The easy part is that you do not need to actually update every account every block; all you do is keep track of the last block during which the account was manipulated and the amount of space taken up by the account in the header RLP and then read just the account every time computation accesses it. The hard part, however, is deleting accounts with negative balance. You might think that you can just scan through all accounts from time to time and then remove the ones with negative balances from the database; the problem is, however, that such a mechanism doesn’t play nicely with Patricia trees. What if a new user joins the network at block 100000, wants to download the state tree, and there are some deleted accounts? Some nodes will have to store the deleted accounts to justify the empty spots, the hashes corresponding to nothing, in the trie. What if a light client wants a proof of execution for some particular transaction? Then the node supplying the proof will have to include the deleted accounts. One approach is to have a “cleansing block” every 100000 blocks that scans through the entire state and clears out the cruft. However, what if there was a more elegant solution?
Treaps
One elegant data structure in computer science is something called a treap. A treap, as one might or probably might not understand from the name, is a structure which is simultaneously a tree and a heap. To review the relevant data structure theory, a heap) is a binary tree, where each node except for leaves has one or two children, where each node has a lower value than its children and the lowest-value node is at the top, and what data structure theorists normally call a tree is a binary tree where values are arranged in sorted order left to right (ie. a node is always greater than its left child and less than its right child, if present). A treap combines the two by having nodes with both a key and a priority; the keys are arranged horizontally and the priorities vertically. Although there can be many heaps for each set of priorities, and many binary trees for each set of values, as it turns out it can be proven that there is always exactly one treap that matches every set of (priority, value)pairs.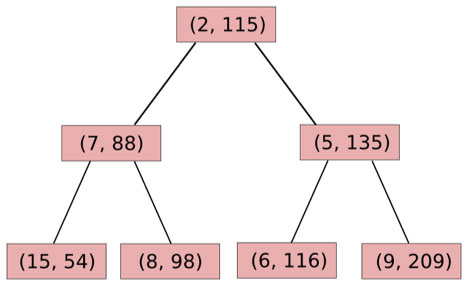
Also, as it turns out, there is an easy (ie. log-time) algorithm for adding and removing a value from the treap, and the mathematical property that there is only one treap for every set of (priority, value) pairs means that treaps are deterministic, and both of these things together make treaps a potential strong candidate for replacing Patricia trees as the state tree data structure. But then, the question is, what would we use for priorities? The answer is simple: the priority of a node is the expected block number at which the node would disappear. The cleaning process would then simply consist of repeatedly kicking off nodes at the top of the treap, a log-time process that can be done at the end of every block.
However, there is one implementation difficulty that makes treaps somewhat challenging for this purpose: treaps are not guaranteed to be shallow. For example, consider the values [[5, 100], [6, 120], [7, 140], [8, 160], [9, 180]]. The treap for those would unfortunately look like this:
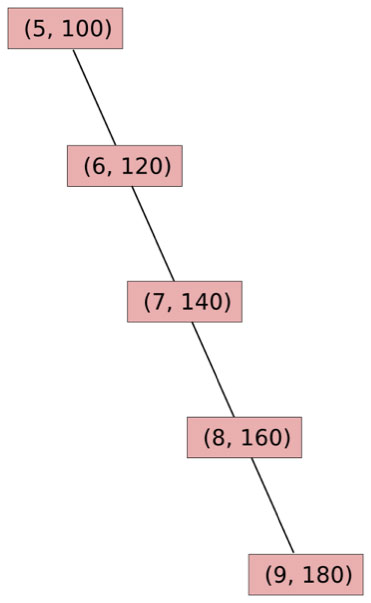
Now, imagine that an attacker generates ten thousand addresses, and puts them into sorted order. The attacker then creates an account with the first private key, and gives it enough ether to survive until block 450000. The attacker then gives the second private key enough ether to survive until block 450001. The third private key lasts until 450002, and so forth until the last account susrvives until block 459999. All of these go into the blockchain. Now, the blockchain will have a chain of ten thousand values each of which is below and to the right of all of the previous. Now, the attacker starts sending transactions to the addresses in the second half of the list. Each of those transactions will require ten thousand database accesses to go through the treap to process. Basically, a denial of service attack through trie manipulation. Can we mitigate this by having the priorities decided according to a more clever semi-randomized algorithm? Not really; even if priorities were completely random, there is an algorithm using which the attacker would be able to generate a 10000-length subsequence of accounts that have both address and priority in increasing order in a hundred million steps. Can we mitigate this by updating the treap bottom-up instead of top-down? Also no; the fact that these are Merkle trees means that we basically have to use functional algorithms to get anywhere.
So what can we do? One approach is to figure out a way to patch this attack. The simplest option would likely involve having a higher cost to purchasing priority the more levels you go down the tree. If the treap is currently 30 levels deep but your addition would increase it to 31 levels, the extra level would be a cost that must be paid for. However, this requires the trie nodes to include a built-in height variable, making the data structure somewhat more complicated and less minimalistic and pure. Another approach is to take the idea behind treaps, and create a data structure that has the same effect using plain old boring Patricia trees. This is the solution that is used in databases such as MySQL, and is called “indices“. Basically, instead of one trie we have two tries. One trie is a mapping of address to account header, and the other trie is a mapping of time-to-live to address. At the end of every block, the left side of the TTL trie is scanned, and as long as there are nodes that need to be deleted they are repeatedly removed from both tries. When a new node is added it is added to both tries, and when a node is updated a naive implementation would update it in both tries if the TTL is changed as a result of the transaction, but a more sophisticated setup might be made where the second update is only done in a more limited subset of cases; for example, one might create a system where a node needs to “purchase TTL” in blocks of 90 days, and this purchase happens automatically every time a node gets onto the chopping block – and if the node is too poor then of course it drops off the edge.
Consequences
So now we have three strategies: treaps with heights, tries with time-to-live indices and the “cleansing block”. Which one works best is an empirical question; the TTL approach would arguably be the easiest to graft onto existing code, but any one of the three could prove most effective assuming the inefficiencies of adding such a system, as well as the usability concerns of having disappearing contracts, are less severe than the gains. What would the effects of any of these strategies be? First of all, some contracts would need to start charging a micro-fee; even passive pieces of code like an elliptic curve signature verifier would need to continually spend funds to justify their existence, and those funds would have to come from somewhere. If a contract cannot afford to do this, then the contract could just store a hash and the onus would be on the transaction sender to send the contract the code that it is supposed to execute; the contract would then check the hash of the code and if the hash matches the code would be run. Name-registry applications might decide to work somewhat differently, storing most of their registrations using some Merkle tree-based offchain mechanism in order to reduce their rent.However, there is also another more subtle consequence: account nonce resets. For example, suppose that I have an account, and I received and sent some transactions from that account. In order to prevent replay attacks (ie. if I send 10 ETH to Bob, Bob should not be able to republish the same transaction in order to get another 10 ETH), each transaction includes a “nonce” counter that increments after every transaction. Thus, the account header stores the current transaction nonce, and if the current nonce is 2 then the only transaction that will be accepted is one with a nonce of 2, at which point the nonce will go up to 3. If accounts disappear, then nonces could reset to 0, leading to potentially dangerous situations if a user accumulates some funds in an account, then lets the balance drop to zero and the account disappear, and then refills it. One solution would be for transactions to have a maximum block number, which can be set to 10 days in the future by defauly, and then require all withdrawals to leave enough balance for the account to last another 10 days; this way, old transactions with nonce 0 would be too old to replay. However, this adds another inefficiency, and must be balanced with the benefit of blockchains charging rent.
As another interesting point, the history of the blockchain would become relevant again; some dapps, wishing to store some data forever, would store it in a transaction instead of the state, and then use past block headers as an immutable rent-free datastore. The existence of applications which do this would mean that Ethereum clients would have to store at least a headers-only version of the history, compromising Ethereum’s “the present state is all that matters” ideology. However, an alternative solution might be to have a contract maintaining a Merkle mountain range, putting the responsibility onto those users that benefit from particular pieces of information being stored to maintain log-sized Merkle tree proofs with the contract remaining under a kilobyte in size.
As a final objection, what if storage space is not the most problematic point of pressure with regard to scalability? What if the main issue is with bandwidth or computation? If the problem is computation, then there are some convenient hacks that can be made; for example, the protocol might be expanded to include both transactions and state transition deltas into the block, and nodes would be free to only check a portion of the deltas (say, 10%) and then quickly gossip about inconsistencies to each other. If it’s bandwidth, then the problem is harder; it means that we simply cannot have every node downloading every transaction, so some kind of tree-chains solution is the only way to move forward. On the other hand, if space is the problem, then rent-charging blockchains are very likely the way to go.