


The crypto 2.0 industry has been making strong progress in the past year developing blockchain technology, including the formalization and in some cases realization of proof of stake designs like Slasher and DPOS, various forms of scalable blockchain algorithms, blockchains using "leader-free consensus" mechanisms derived from traditional Byzantine fault tolerance theory, as well as economic ingredients like Schelling consensus schemes and stable currencies. All of these technologies remedy key deficiencies of the blockchain design with respect to centralized servers: scalability knocks down size limits and transaction costs, leader-free consensus reduces many forms of exploitability, stronger PoS consensus algorithms reduce consensus costs and improve security, and Schelling consensus allows blockchains to be "aware" of real-world data. However, there is one piece of the puzzle that all approaches so far have not yet managed to crack: privacy.
Currency, Dapps and Privacy
Bitcoin brings to its users a rather unique set of tradeoffs with respect to financial privacy. Although Bitcoin does a substantially better job than any system that came before it at protecting the physical identities behind each of its accounts - better than fiat and banking infrastructure because it requires no identity registration, and better than cash because it can be combined with Tor to completely hide physical location, the presence of the Bitcoin blockchain means that the actual transactions made by the accounts are more public than ever - neither the US government, nor China, nor the thirteen year old hacker down the street even need so much as a warrant in order to determine exactly which account sent how much BTC to which destination at what particular time. In general, these two forces pull Bitcoin in opposite directions, and it is not entirely clear which one dominates.
With Ethereum, the situation is similar in theory, but in practice it is rather different. Bitcoin is a blockchain intended for currency, and currency is inherently a very fungible thing. There exist techniques like merge avoidance which allow users to essentially pretend to be 100 separate accounts, with their wallet managing the separation in the background. Coinjoin can be used to "mix" funds in a decentralized way, and centralized mixers are a good option too especially if one chains many of them together. Ethereum, on the other hand, is intended to store intermediate state of any kind of processes or relationships, and unfortunately it is the case that many processes or relationships that are substantially more complex than money are inherently "account-based", and large costs would be incurred by trying to obfuscate one's activities via multiple accounts. Hence, Ethereum, as it stands today, will in many cases inherit the transparency side of blockchain technology much more so than the privacy side (although those interested in using Ethereum for currency can certainly build higher-privacy cash protocols inside of subcurrencies).
Now, the question is, what if there are cases where people really want privacy, but a Diaspora-style self-hosting-based solution or a Zerocash-style zero-knowledge-proof strategy is for whatever reason impossible - for example, because we want to perform calculations that involve aggregating multiple users' private data? Even if we solve scalability and blockchain data assets, will the lack of privacy inherent to blockchains mean that we simply have to go back to trusting centralized servers? Or can we come up with a protocol that offers the best of both worlds: a blockchain-like system which offers decentralized control not just over the right to update the state, but even over the right to access the information at all?
As it turns out, such a system is well within the realm of possibility, and was even conceptualized by Nick Szabo in 1998 under the moniker of "God protocols" (though, as Nick Szabo pointed out, we should not use that term for the protocols that we are about to describe here as God is generally assumed or even defined to be Pareto-superior to everything else and as we'll soon see these protocols are very far from that); but now with the advent of Bitcoin-style cryptoeconomic technology the development of such a protocol may for the first time actually be viable. What is this protocol? To give it a reasonably technically accurate but still understandable term, we'll call it a "secret sharing DAO".
Fundamentals: Secret Sharing
To skip the fun technical details and go straight to applications, click here
Secret computation networks rely on two fundamental primitives to store information in a decentralized way. The first is secret sharing. Secret sharing essentially allows data to be stored in a decentralized way across N parties such that any K parties can work together to reconstruct the data, but K-1 parties cannot recover any information at all. N and K can be set to any values desired; all it takes is a few simple parameter tweaks in the algorithm.
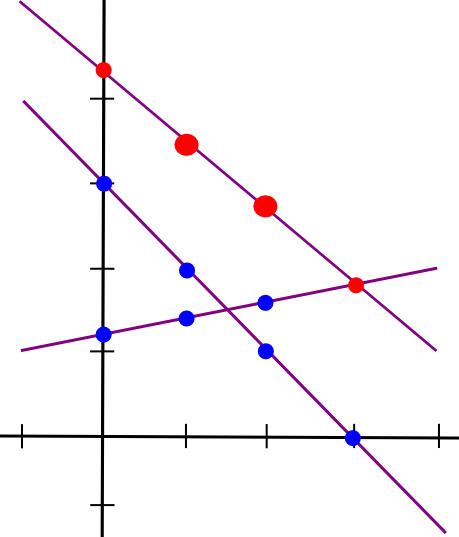
The simplest way to mathematically describe secret sharing is as follows. We know that two points make a line:
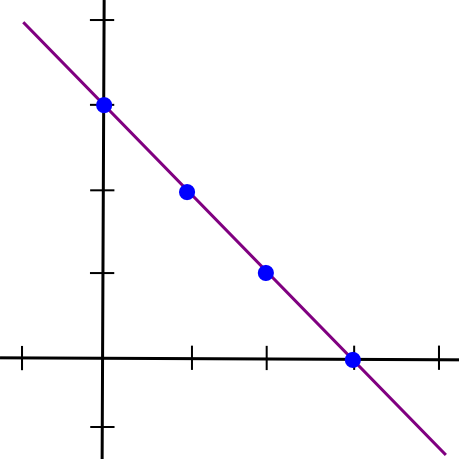
So, to implement 2-of-N secret sharing, we take our secret S, generate a random slope m, and create the line y = mx + S. We then give the N parties the points on the line (1, m + S), (2, 2m + S), (3, 3m + S), etc. Any two of them can reconstruct the line and recover the original secret, but one person can do nothing; if you receive the point (4, 12), that could be from the line y = 2x + 4, or y = -10x + 52, or y = 305445x - 1221768. To implement 3-of-N secret sharing, we just make a parabola instead, and give people points on the parabola:
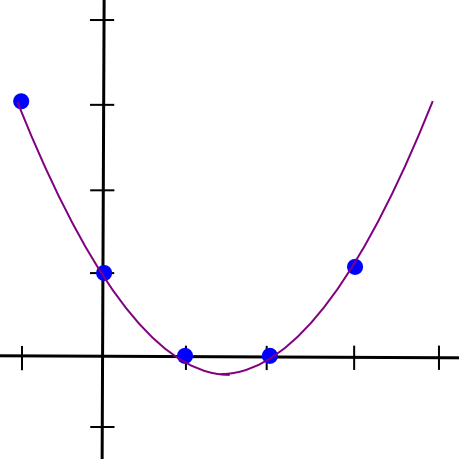
Parabolas have the property that any three points on a parabola can be used to reconstruct the parabola (and no one or two points suffice), so essentially the same process applies. And, more generally, to implement K-of-N secret sharing, we use a degree K-1 polynomial in the same way. There is a set of algorithms for recovering the polynomial from a sufficient set of points in all such cases; they are described in more details in our earlier article on erasure coding.
This is how the secret sharing DAO will store data. Instead of every participating node in the consensus storing a copy of the full system state, every participating node in the consensus will store a set of shares of the state - points on polynomials, one point on a different polynomial for each variable that makes up part of the state.
Fundamentals: Computation
Now, how does the secret sharing DAO do computation? For this, we use a set of algorithms called secure multiparty computation (SMPC). The basic principle behind SMPC is that there exist ways to take data which is split among N parties using secret sharing, perform computations on it in a decentralized way, and end up with the result secret-shared between the parties, all without ever reconstituting any of the data on a single device.
SMPC with addition is easy. To see how, let's go back to the two-points-make-a-line example, but now let's have two lines:
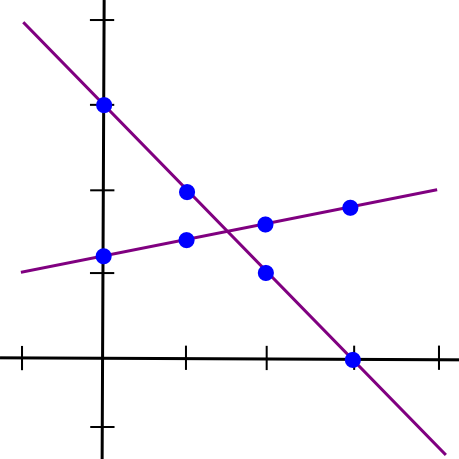
Suppose that the x=1 point of both lines A and B is stored by computer P[1], the x=2 point is stored by computer P[2], etc. Now, suppose that P[1] computes a new value, C(1) = A(1) + B(1), and B computes C(2) = A(2) + B(2). Now, let's draw a line through those two points:
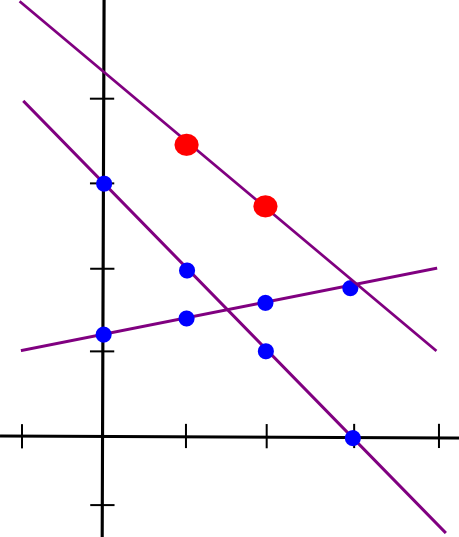
So we have a new line, C, such that C = A + B at points x=1 and x=2. However, the interesting thing is, this new line is actually equal to A + B on every point:
Thus, we have a rule: sums of secret shares (at the same x coordinate) are secret shares of the sum. Using this principle (which also applies to higher dimensions), we can convert secret shares of a and secret shares of b into secret shares of a+b, all without ever reconstituting a and b themselves. Multiplication by a known constant value works the same way: k times the ith secret share of a is equal to the ith secret share of a*k.
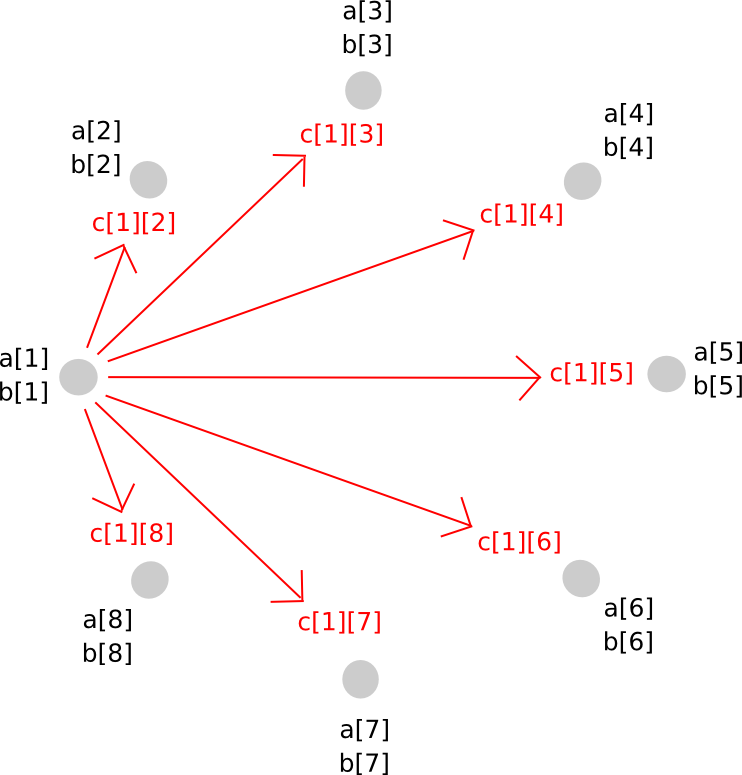
Multiplication of two secret shared values, unfortunately, is much more involved. The approach will take several steps to explain, and because it is fairly complicated in any case it's worth simply doing for arbitrary polynomials right away. Here's the magic. First, suppose that there exist values a and b, secret shared among parties P[1] ... P[n], where a[i] represents the ith share of a (and same for b[i] and b). We start off like this:
Now, one option that you might think of is, if we can just make a new polynomial c = a + b by having every party store c[i] = a[i] + b[i], can't we do the same for multiplication as well? The answer is, surprisingly, yes, but with a serious problem: the new polynomial has a degree twice as large as the original. For example, if the original polynomials were y = x + 5 and y = 2x - 3, the product would be y = 2x^2 + 7x - 15. Hence, if we do multiplication more than once, the polynomial would become too big for the group of N to store.
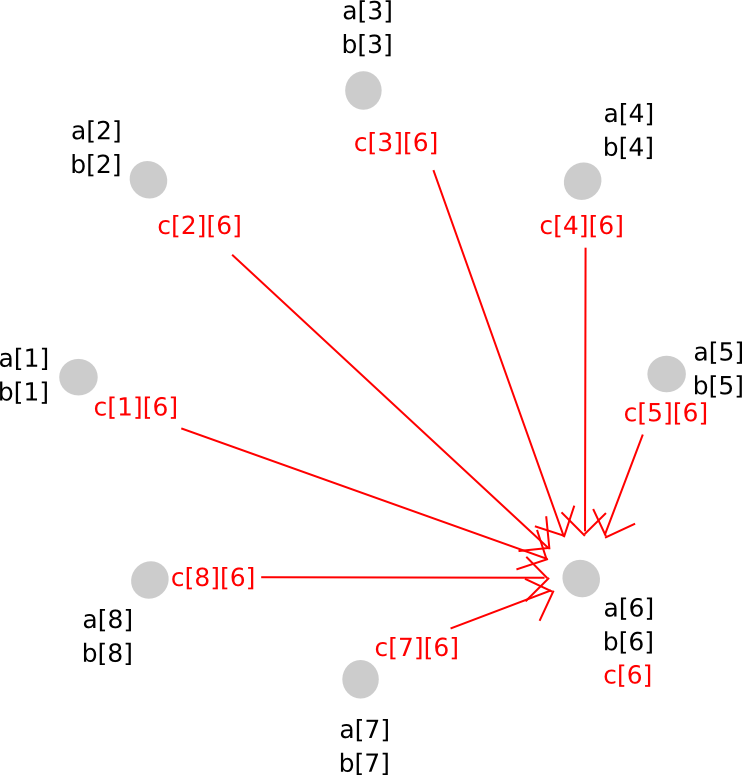
To avoid this problem, we perform a sort of rebasing protocol where we convert the shares of the larger polynomial into shares of a polynomial of the original degree. The way it works is as follows. First, party P[i] generates a new random polynomial, of the same degree as a and b, which evaluates to c[i] = a[i]*b[i] at zero, and distributes points along that polynomial (ie. shares of c[i]) to all parties.
Thus, P[j] now has c[i][j] for all i. Given this, P[j] calculates c[j], and so everyone has secret shares of c, on a polynomial with the same degree as a and b.
To do this, we used a clever trick of secret sharing: because the secret sharing math itself involves nothing more than additions and multiplications by known constants, the two layers of secret sharing are commutative: if we apply secret sharing layer A and then layer B, then we can take layer A off first and still be protected by layer B. This allows us to move from a higher-degree polynomial to a lower degree polynomial but avoid revealing the values in the middle - instead, the middle step involved both layers being applied at the same time.
With addition and multiplication over 0 and 1, we have the ability to run arbitrary circuits inside of the SMPC mechanism. We can define:
- AND(a, b) = a * b
- OR(a, b) = a + b - a * b
- XOR(a, b) = a + b - 2 * a * b
- NOT(a) = 1 - a
Hence, we can run whatever programs we want, although with one key limitation: we can't do secret conditional branching. That is, if we had a computation if (x == 5) <do A> else <do B> then the nodes would need to know whether they are computing branch A or branch B, so we would need to reveal x midway through.
There are two ways around this problem. First, we can use multiplication as a "poor man's if" - replace something like if (x == 5) <y = 7> with y = (x == 5) * 7 + (x != 5) * y, using either circuits or clever protocols that implement equality checking through repeated multiplication (eg. if we are in a finite field we can check if a == b by using Fermat's little theorem on a-b). Second, as we will see, if we implement if statements inside the EVM, and run the EVM inside SMPC, then we can resolve the problem, leaking only the information of how many steps the EVM took before computation exited (and if we really care, we can reduce the information leakage further, eg. round the number of steps to the nearest power of two, at some cost to efficiency).
The secret-sharing based protocol described above is only one way to do relatively simply SMPC; there are other approaches, and to achieve security there is also a need to add a verifiable secret sharing layer on top, but that is beyond the scope of this article - the above description is simply meant to show how a minimal implementation is possible.
Building a Currency
Now that we have a rough idea of how SMPC works, how would we use it to build a decentralized currency engine? The general way that a blockchain is usually described in this blog is as a system that maintains a state, S, accepts transactions, agrees on which transactions should be processed at a given time and computes a state transition function APPLY(S, TX) -> S' OR INVALID. Here, we will say that all transactions are valid, and if a transaction TX is invalid then we simply have APPLY(S, TX) = S.
Now, since the blockchain is not transparent, we might expect the need for two kinds of transactions that users can send into the SMPC: get requests, asking for some specific information about an account in the current state, and update requests, containing transactions to apply onto the state. We'll implement the rule that each account can only ask for balance and nonce information about itself, and can withdraw only from itself. We define the two types of requests as follows:
SEND: [from_pubkey, from_id, to, value, nonce, sig] GET: [from_pubkey, from_id, sig]
The database is stored among the N nodes in the following format:
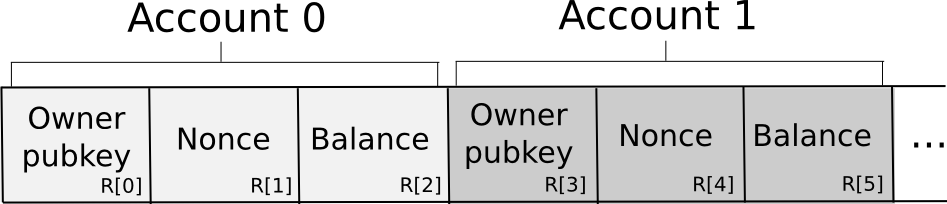
Essentially, the database is stored as a set of 3-tuples representing accounts, where each 3-tuple stores the owning pubkey, nonce and balance. To send a request, a node constructs the transaction, splits it off into secret shares, generates a random request ID and attaches the ID and a small amount of proof of work to each share. The proof of work is there because some anti-spam mechanism is necessary, and because account balances are private there is no way if the sending account has enough funds to pay a transaction fee. The nodes then independently verify the shares of the signature against the share of the public key supplied in the transaction (there are signature algorithms that allow you to do this kind of per-share verification; Schnorr signatures are one major category). If a given node sees an invalid share (due to proof of work or the signature), it rejects it; otherwise, it accepts it.
Transactions that are accepted are not processed immediately, much like in a blockchain architecture; at first, they are kept in a memory pool. At the end of every 12 seconds, we use some consensus algorithm - it could be something simple, like a random node from the N deciding as a dictator, or an advanced neo-BFT algorithm like that used by Pebble - to agree on which set of request IDs to process and in which order (for simplicity, simple alphabetical order will probably suffice).
Now, to fufill a GET request, the SMPC will compute and reconstitute the output of the following computation:
owner_pubkey = R[0] * (from_id == 0) + R[3] * (from_id == 1) + ... + R[3*n] * (from_id == n) valid = (owner_pubkey == from_pubkey) output = valid * (R[2] * (from_id == 0) + R[5] * (from_id == 1) + ... + R[3n + 2] * (from_id == n))
So what does this formula do? It consists of three stages. First, we extract the owner pubkey of the account that the request is trying to get the balance of. Because the computation is done inside of an SMPC, and so no node actually knows what database index to access, we do this by simply taking all the database indices, multiplying the irrelevant ones by zero and taking the sum. Then, we check if the request is trying to get data from an account which is actually owns (remember that we checked the validity of from_pubkey against the signature in the first step, so here we just need to check the account ID against the from_pubkey). Finally, we use the same database getting primitive to get the balance, and multiply the balance by the validity to get the result (ie. invalid requests return a balance of 0, valid ones return the actual balance).
Now, let's look at the execution of a SEND. First, we compute the validity predicate, consisting of checking that (1) the public key of the targeted account is correct, (2) the nonce is correct, and (3) the account has enough funds to send. Note that to do this we once again need to use the "multiply by an equality check and add" protocol, but for brevity we will abbreviate R[0] * (x == 0) + R[3] * (x == 1) + ... with R[x * 3].
valid = (R[from_id * 3] == from_pubkey) * (R[from_id * 3 + 1] == nonce) * (R[from_id * 3 + 2] >= value)
We then do:
R[from_id * 3 + 2] -= value * valid R[from_id * 3 + 1] += valid R[to * 3 + 2] += value * valid
For updating the database, R[x * 3] += y expands to the set of instructions R[0] += y * (x == 0), R[3] += y * (x == 1) .... Note that all of these can be parallelized. Also, note that to implement balance checking we used the >= operator. This is once again trivial using boolean logic gates, but even if we use a finite field for efficiency there do exist some clever tricks for performing the check using nothing but additions and multiplications.
In all of the above we saw two fundamental limitations in efficiency in the SMPC architecture. First, reading and writing to a database has an O(n) cost as you pretty much have to read and write every cell. Doing anything less would mean exposing to individual nodes which subset of the database a read or write was from, opening up the possibility of statistical memory leaks. Second, every multiplication requires a network message, so the fundamental bottleneck here is not computation or memory but latency. Because of this, we can already see that secret sharing networks are unfortunately not God protocols; they can do business logic just fine, but they will never be able to do anything more complicated - even crypto verifications, with the exception of a select few crypto verifications specifically tailored to the platform, are in many cases too expensive.
From Currency to EVM
Now, the next problem is, how do we go from this simple toy currency to a generic EVM processor? Well, let us examine the code for the virtual machine inside a single transaction environment. A simplified version of the function looks roughly as follows:
def run_evm(block, tx, msg, code): pc = 0 gas = msg.gas stack = [] stack_size = 0 exit = 0 while 1: op = code[pc] gas -= 1 if gas < 0 or stack_size < get_stack_req(op): exit = 1 if op == ADD: x = stack[stack_size] y = stack[stack_size - 1] stack[stack_size - 1] = x + y stack_size -= 1 if op == SUB: x = stack[stack_size] y = stack[stack_size - 1] stack[stack_size - 1] = x - y stack_size -= 1 ... if op == JUMP: pc = stack[stack_size] stack_size -= 1 ...
The variables involved are:
- The code
- The stack
- The memory
- The account state
- The program counter
Hence, we can simply store these as records, and for every computational step run a function similar to the following:
op = code[pc] * alive + 256 * (1 - alive) gas -= 1 stack_p1[0] = 0 stack_p0[0] = 0 stack_n1[0] = stack[stack_size] + stack[stack_size - 1] stack_sz[0] = stack_size - 1 new_pc[0] = pc + 1 stack_p1[1] = 0 stack_p0[1] = 0 stack_n1[1] = stack[stack_size] - stack[stack_size - 1] stack_sz[1] = stack_size - 1 new_pc[1] = pc + 1 ... stack_p1[86] = 0 stack_p0[86] = 0 stack_n1[86] = stack[stack_size - 1] stack_sz[86] = stack_size - 1 new_pc[86] = stack[stack_size] ... stack_p1[256] = 0 stack_p0[256] = 0 stack_n1[256] = 0 stack_sz[256] = 0 new_pc[256] = 0 pc = new_pc[op] stack[stack_size + 1] = stack_p1[op] stack[stack_size] = stack_p0[op] stack[stack_size - 1] = stack_n1[op] stack_size = stack_sz[op] pc = new_pc[op] alive *= (gas < 0) * (stack_size < 0)
Essentially, we compute the result of every single opcode in parallel, and then pick the correct one to update the state. The alive variable starts off at 1, and if the alive variable at any point switches to zero, then all operations from that point simply do nothing. This seems horrendously inefficient, and it is, but remember: the bottleneck is not computation time but latency. Everything above can be parallelized. In fact, the astute reader may even notice that the entire process of running every opcode in parallel has only O(n) complexity in the number of opcodes (particularly if you pre-grab the top few items of the stack into specified variables for input as well as output, which we did not do for brevity), so it is not even the most computationally intensive part (if there are more accounts or storage slots than opcodes, which seems likely, the database updates are). At the end of every N steps (or for even less information leakage every power of two of steps) we reconstitute the alive variable and if we see that alive = 0 then we halt.
In an EVM with many participants, the database will likely be the largest overhead. To mitigate this problem, there are likely clever information leakage tradeoffs that can be made. For example, we already know that most of the time code is read from sequential database indices. Hence, one approach might be to store the code as a sequence of large numbers, each large number encoding many opcodes, and then use bit decomposition protocols to read off individual opcodes from a number once we load it. There are also likely many ways to make the virtual machine fundamentally much more efficient; the above is meant, once again, as a proof of concept to show how a secret sharing DAO is fundamentally possible, not anything close to an optimal implementation. Additionally, we can look into architectures similar to the ones used in scalability 2.0 techniques to highly compartmentalize the state to further increase efficiency.
Updating the N
The SMPC mechanism described above assumes an existing N parties involved, and aims to be secure against any minority of them (or in some designs at least any minority less than 1/4 or 1/3) colluding. However, blockchain protocols need to theoretically last forever, and so stagnant economic sets do not work; rather, we need to select the consensus participants using some mechanism like proof of stake. To do this, an example protocol would work as follows:
- The secret sharing DAO's time is divided into "epochs", each perhaps somewhere between an hour and a week long.
- During the first epoch, the participants are set to be the top N participants during the genesis sale.
- At the end of an epoch, anyone has the ability to sign up to be one of the participants in the next round by putting down a deposit. N participants are randomly chosen, and revealed.
- A "decentralized handoff protocol" is carried out, where the N participants simultaneously split their shares among the new N, and each of the new N reconstitutes their share from the pieces that they received - essentially, the exact same protocol as was used for multiplication. Note that this protocol can also be used to increase or decrease the number of participants.
All of the above handles decentralization assuming honest participants; but in a cryptocurrency protocol we also need incentives. To accomplish that, we use a set of primitives called verifiable secret sharing, that allow us to determine whether a given node was acting honestly throughout the secret sharing process. Essentially, this process works by doing the secret sharing math in parallel on two different levels: using integers, and using elliptic curve points (other constructions also exist, but because cryptocurrency users are most familiar with the secp256k1 elliptic curve we'll use that). Elliptic curve points are convenient because they have a commutative and associative addition operator - in essence, they are magic objects which can be added and subtracted much like numbers can. You can convert a number into a point, but not a point into a number, and we have the property that number_to_point(A + B) = number_to_point(A) + number_to_point(B). By doing the secret sharing math on the number level and the elliptic curve point level at the same time, and publicizing the elliptic curve points, it becomes possible to verify malfeasance. For efficiency, we can probably use a Schellingcoin-style protocol to allow nodes to punish other nodes that are malfeasant.
Applications
So, what do we have? If the blockchain is a decentralized computer, a secret sharing DAO is a decentralized computer with privacy. The secret sharing DAO pays dearly for this extra property: a network message is required per multiplication and per database access. As a result, gas costs are likely to be much higher than Ethereum proper, limiting the computation to only relatively simple business logic, and barring the use of most kinds of cryptographic calculations. Scalability technology may be used to partially offset this weakness, but ultimately there is a limit to how far you can get. Hence, this technology will probably not be used for every use case; instead, it will operate more like a special-purpose kernel that will only be employed for specific kinds of decentralized applications. Some examples include:
- Medical records - keeping the data on a private decentralized platform can potentially open the door for an easy-to-use and secure health information system that keeps patients in control of their data. Particularly, note that proprietary diagnosis algorithms could run inside the secret sharing DAO, allowing medical diagnosis as a service based on data from separate medical checkup firms without running the risk that they will intentionally or unintentionally expose your private details to insurers, advertisers or other firms.
- Private key escrow - a decentralized M-of-N alternative to centralized password recovery; could be used for financial or non-financial applications
- Multisig for anything - even systems that do not natively support arbitrary access policies, or even M-of-N multisignature access, now will, since as long as they support cryptography you can stick the private key inside of a secret sharing DAO.
- Reputation systems - what if reputation scores were stored inside a secret sharing DAO so you could privately assign reputation to other users, and have your assignment count towards the total reputation of that user, without anyone being able to see your individual assignments?
- Private financial systems - secret sharing DAOs could provide an alternative route to Zerocash-style fully anonymous currency, except that here the functionality could be much more easily extended to decentralized exchange and more complex smart contracts. Business users may want to leverage some of the benefits of running their company on top of crypto without necessarily exposing every single one of their internal business processes to the general public.
- Matchmaking algorithms - find employers, employees, dating partners, drivers for your next ride on Decentralized Uber, etc, but doing the matchmaking algorithm computations inside of SMPC so that no one sees any information about you unless the algorithm determines that you are a perfect match.
Essentially, one can think of SMPC as offering a set of tools roughly similar to that which it has been theorized would be offered by cryptographically secure code obfuscation, except with one key difference: it actually works on human-practical time scales.
Further Consequences
Aside from the applications above, what else will secret sharing DAOs bring? Particularly, is there anything to worry about? As it turns out, just like with blockchains themselves, there are a few concerns. The first, and most obvious, issue is that secret sharing DAOs will substantially increase the scope of applications that can be carried out in a completely private fashion. Many advocates of blockchain technology often base a large part of their argument on the key point that while blockchain-based currencies offer an unprecedented amount of anonymity in the sense of not linking addresses to individual identities, they are at the same time the most public form of currency in the world because every transaction is located on a shared ledger. Here, however, the first part remains, but the second part disappears completely. What we have left is essentially total anonymity.
If it turns out to be the case that this level of anonymity allows for a much higher degree of criminal activity, and the public is not happy with the tradeoff that the technology brings, then we can predict that governments and other institutions in general, perhaps even alongside volunteer vigilante hackers, will try their best to take these systems down, and perhaps they would even be justified. Fortunately for these attackers, however, secret sharing DAOs do have an inevitable backdoor: the 51% attack. If 51% of the maintainers of a secret sharing DAO at some particular time decide to collude, then they can uncover any of the data that is under their supervision. Furthermore, this power has no statute of limitations: if a set of entities who formed over half of the maintaining set of a secret sharing DAO at some point many years ago collude, then even then the group would be able to unearth the information from that point in time. In short, if society is overwhelmingly opposed to something being done inside of a secret sharing DAO, there will be plenty of opportunity for the operators to collude to stop or reveal what's going on.
A second, and subtler, issue is that the concept of secret sharing DAOs drives a stake through a cherished fact of cryptoeconomics: that private keys are not securely tradeable. Many protocols explicitly, or implicitly, rely on this idea, including non-outsourceable proof of work puzzles, Vlad Zamfir and Pavel Kravchenko's proof of custody, economic protocols that use private keys as identities, any kind of economic status that aims to be untradeable, etc. Online voting systems often have the requirement that it should be impossible to prove that you voted with a particular key, so as to prevent vote selling; with secret sharing DAOs, the problem is that now you actually can sell your vote, rather simply: by putting your private key into a contract inside of a secret sharing DAO, and renting out access.
The consequences of this ability to sell private keys are quite far reaching - in fact, they go so far as to almost threaten the security of the strongest available system underlying blockchain security: proof of stake. The potential concern is this: proof of stake derives its security from the fact that users have security deposits on the blockchain, and these deposits can potentially be taken away if the user misacts in some fashion (double-voting, voting for a fork, not voting at all, etc). Here, private keys become tradeable, and so security deposits become tradeable as well. We must ask the question: does this compromise proof of stake?
Fortunately, the answer is no. First of all, there are strong lemon-theoretic arguments for why no one would actually want to sell their deposit. If you have a deposit of $10, to you that's worth $10 minus the tiny probability that you will get hacked. But if you try to sell that deposit to someone else, they will have a deposit which is worth $10, unless you decide to use your private key to double-vote and thus destroy the deposit. Hence, from their point of view, there is a constant overhanging risk that you will act to take their deposit away, and you personally have no incentive not to do that. The very fact that you are trying to sell off your deposit should make them suspicious. Hence, from their point of view, your deposit might only be worth, say, $8. You have no reason to sacrifice $10 for $8, so as a rational actor you will keep the deposit to yourself.
Second, if the private key was in the secret sharing DAO right from the start, then by transferring access to the key you would personally lose access to it, so you would actually transfer the authority and the liability at the same time - from an economic standpoint, the effect on the system would be exactly the same as if one of the deposit holders simply had a change of personality at some point during the process. In fact, secret sharing DAOs may even improve proof of stake, by providing a more secure platform for users to participate in decentralized stake pools even in protocols like Tendermint, which do not natively support such functionality.
There are also other reasons why the theoretical attacks that secret sharing DAOs make possible may in fact fail in practice. To take one example, consider the case of non-outsourceable puzzles, computational problems which try to prove ownership of a private key and a piece of data at the same time. One kind of implementation of a non-outsourceable puzzle, used by Permacoin, involves a computation which needs to "bounce" back and forth between the key and the data hundreds of thousands of times. This is easy to do if you have the two pieces of data on the same piece of hardware, but becomes prohibitively slow if the two are separated by a network connection - and over a secret sharing DAO it would be nearly impossible due to the inefficiencies. As a result, one possible conclusion of all this is that secret sharing DAOs will lead to the standardization of a signature scheme which requires several hundred millions of rounds of computation - preferably with lots and lots of serial multiplication - to compute, at which point every computer, phone or internet-of-things microchip would have a built-in ASIC to do it trivially, secret sharing DAOs would be left in the dust, and we would all move on with our lives.
How Far Away?
So what is left before secret sharing DAO technology can go mainstream? In short, quite a bit, but not too much. At first, there is certainly a moderate amount of technical engineering involved, at least on the protocol level. Someone needs to formalize an SMPC implementation, together with how it would be combined with an EVM implementation, probably with many restrictions for efficiency (eg. hash functions inside of SMPC are very expensive, so Merkle tree storage may disappear in favor of every contract having a finite number of storage slots), a punishment, incentive and consensus framework and a hypercube-style scalability framework, and then release the protocol specification. From that point, it's a few months of development in Python (Python should be fine, as by far the primary bottleneck will be network latency, not computation), and we'll have a working proof of concept.
Secret sharing and SMPC technology has been out there for many years, and academic cryptographers have been talking about how to build privacy-preserving applications using M-of-N-based primitives and related technologies such as private information retrieval for over a decade. The key contribution made by Bitcoin, however, is the idea that M-of-N frameworks in general can be much more easily bootstrapped if we add in an economic layer. A secret sharing DAO with a currency built in would provide incentives for individuals to participate in maintaining the network, and would bootstrap it until the point where it could be fully self-sustaining on internal applications. Thus, altogether, this technology is quite possible, and not nearly so far away; it is only a matter of time until someone does it.